Chasing Geometric Structure in Transformers
I spent two weeks searching for a geometric structure in transformers.
The previous posts showed that single-layer ReLU networks with totally positive weight matrices have positroid matroid structure — a clean combinatorial pattern that identifies which neurons are safe to prune. Matroid-guided pruning removes 70% of neurons with zero accuracy loss, strictly beating every standard heuristic.
That result raised an obvious question: how deep does this go?
Before Transformers
I first tried the obvious extension: multi-layer networks. In a two-hidden-layer ReLU network, the second layer acts as a linear mixer, combining first-layer rows into effective rows that land in general position. I computed the effective matroid across ~2,600 activation regions in networks of varying size. Every one was uniform — the trivial matroid. Positroid structure doesn’t survive composition through ReLU.
But the determinant itself — the tool for detecting matroid dependencies — turned out to be a useful nonlinearity. I built a standalone classifier whose decision function is \(\det(B(t) \cdot Z(x))\), where \(B(t) \in \text{Gr}_+(k,n)\) is a learned boundary measurement and \(Z(x)\) encodes the input. For \(k=3\), this determinant is quadratic in \(x\), giving the network curved decision boundaries. On 2D tasks, the \(k=3\) positroid network hit 100% on circles and XOR where a matched-parameter ReLU got 76% and 80% — a genuine geometric advantage when the data has algebraic structure.
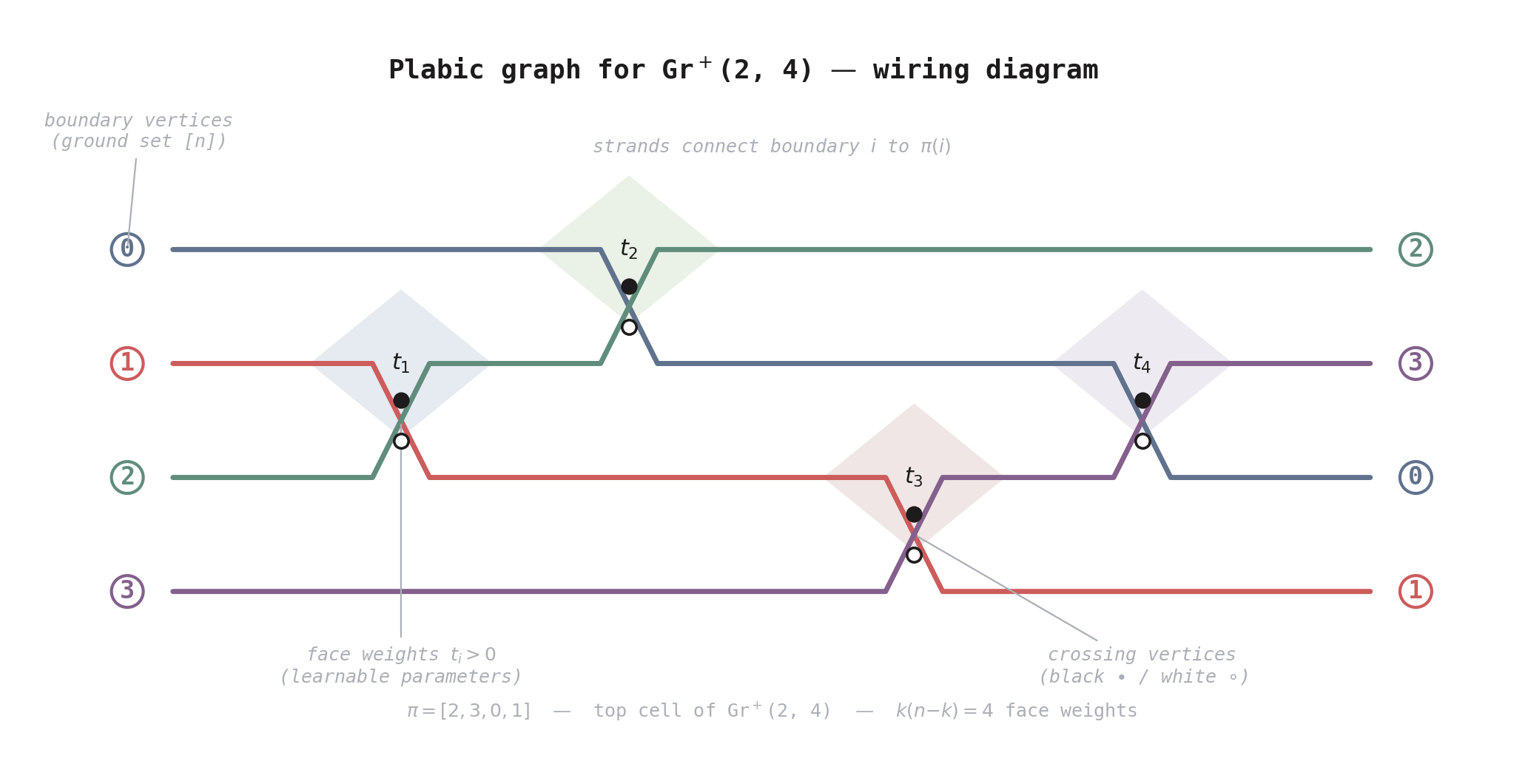
Figure 1. Wiring diagram for the plabic graph of Gr\(^+\)(2, 4). The four colored strands connect boundary vertices \(i\) to \(\pi(i)\), crossing at four points corresponding to the reduced word \([s_1, s_0, s_2, s_1]\). Each crossing has a black/white vertex pair (routing rules) and a bounded face with a learnable face weight \(t_i > 0\). The \(k(n{-}k) = 4\) face weights parameterize a point in the totally positive Grassmannian and define the boundary measurement matrix \(B(t)\).
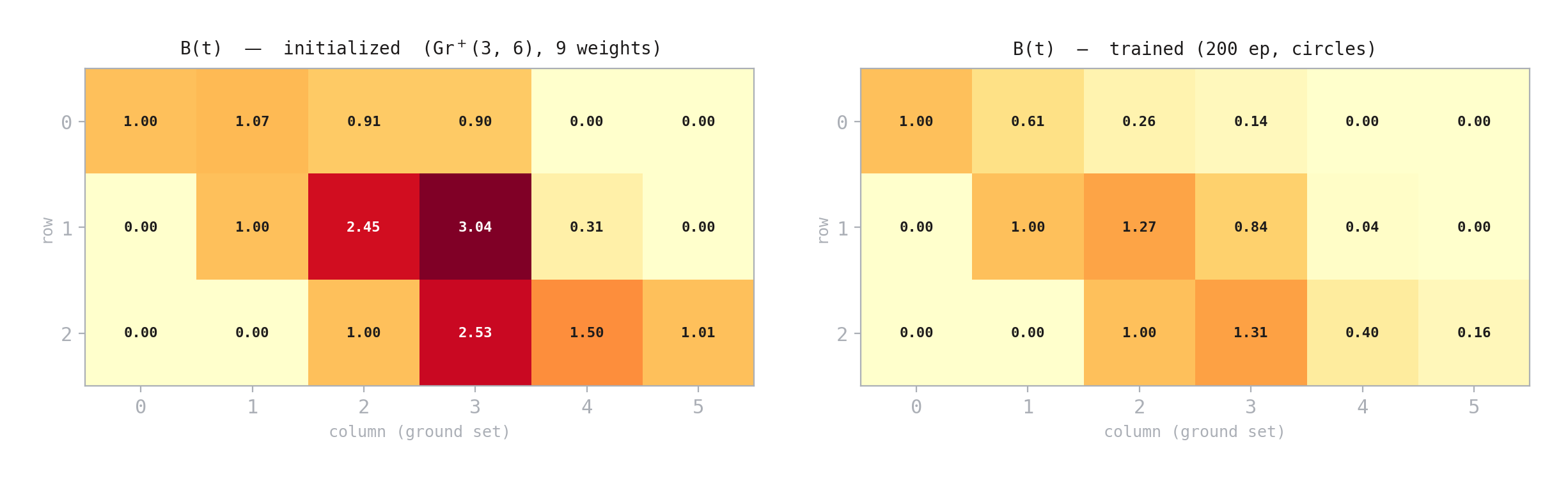
Figure 2. The 3×6 boundary measurement matrix \(B(t) \in \text{Gr}^+(3, 6)\) before and after training on the circles dataset (9 face weights). Training reshapes \(B\) from near-identity to a structured matrix that captures the data geometry.
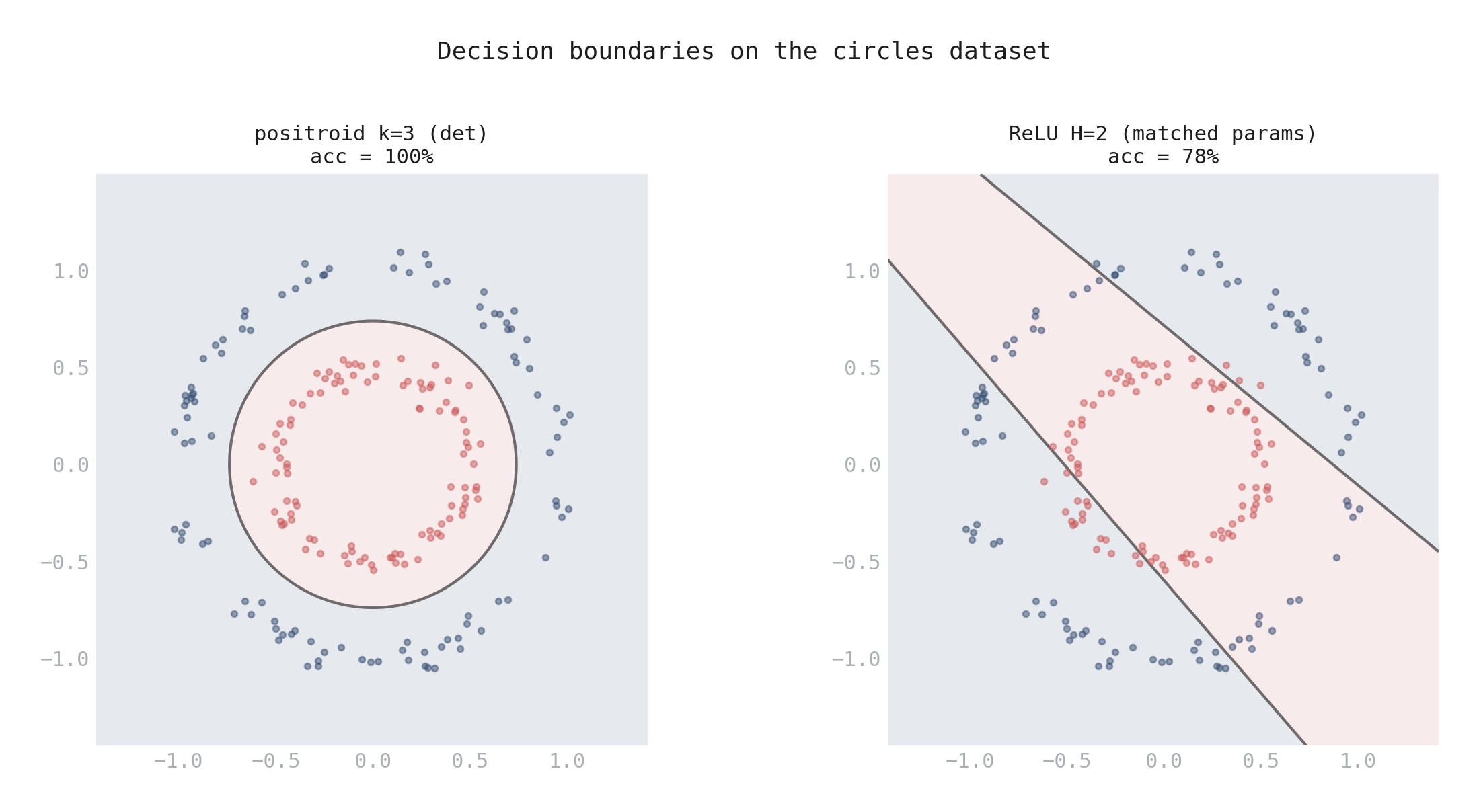
Figure 3. Decision boundaries on the circles dataset. Left: the k=3 positroid network learns a curved boundary that perfectly separates the concentric rings (100%). Right: a matched-parameter ReLU with H=2 neurons can only produce linear cuts (78%).
Extending to 10-class digit classification, the architecture scaled cleanly: \(k=2\) with learnable encoding matched ReLU at 100% accuracy on 50-dimensional inputs. But it needed 3.6x more parameters and ran ~20x slower. The geometric architecture had real expressiveness but poor efficiency, and the gap grew with dimension.
This set up the transformer question. Could embedding positroid components inside a transformer — sharing structure across layers and heads — change the efficiency story? And more ambitiously: did trained transformers already have this structure, waiting to be found?
The idea — inspired by the amplituhedron from particle physics — was that neural networks might have an analogous geometric structure built on the positive Grassmannian. I formalized this into four testable predictions, built the components, and ran a series of experiments — systematically falsifying almost everything.
The Hypothesis
In quantum field theory, computing scattering amplitudes traditionally requires summing over enormous numbers of Feynman diagrams. But for certain theories, this sum can be computed from a geometric object — the amplituhedron — constructed from the totally nonneg Grassmannian \(\text{Gr}_+(k,n)\). The combinatorics of this object are governed by positroids, the same structures that showed up in my ReLU network experiments.
The question: does an analogous geometric structure exist for neural network computation? If so, it might simplify or improve how we build models — the way the amplituhedron simplifies scattering calculations.
I made this concrete with four predictions:
- Weight matrices are approximately totally positive. Trained transformer weight matrices should have nonneg minors, placing them near \(\text{Gr}_+(k,n)\).
- Attention patterns exhibit positroid structure. Attention matrices (after softmax) should have positroid-structured submatrices.
- Positroid-constrained MLPs improve efficiency. Replacing standard MLPs with boundary-measurement-parameterized determinant MLPs should maintain accuracy with fewer parameters.
- Positroid attention is competitive. Replacing QKV dot-product attention with boundary-measurement-based attention scores should match standard performance.
Each is testable and falsifiable.
Building Positroid Transformer Components
Before testing existing transformers, I built positroid versions of each component from scratch.
Positroid attention replaces the dot-product score \(q^T W_Q^T W_K v\) with a boundary measurement: face weights define a point in \(\text{Gr}_+(k, n)\), and the attention score between tokens \(i\) and \(j\) is the maximal minor of the boundary measurement matrix formed by columns \(i\) and \(j\). For \(k = 2\), this produces antisymmetric scores (\(s_{ij} = -s_{ji}\)) with a learnable self-bias on the diagonal.
The tropical MLP replaces the standard ReLU expansion (\(W_2 \cdot \text{ReLU}(W_1 x + b)\)) with a determinant nonlinearity: encode the input into the columns of a matrix \(B\) parameterized as a boundary measurement on \(\text{Gr}_+(k,n)\), compute the maximal minors, and read out via a learned projection. This trades the 4x width expansion for a compact geometric representation.
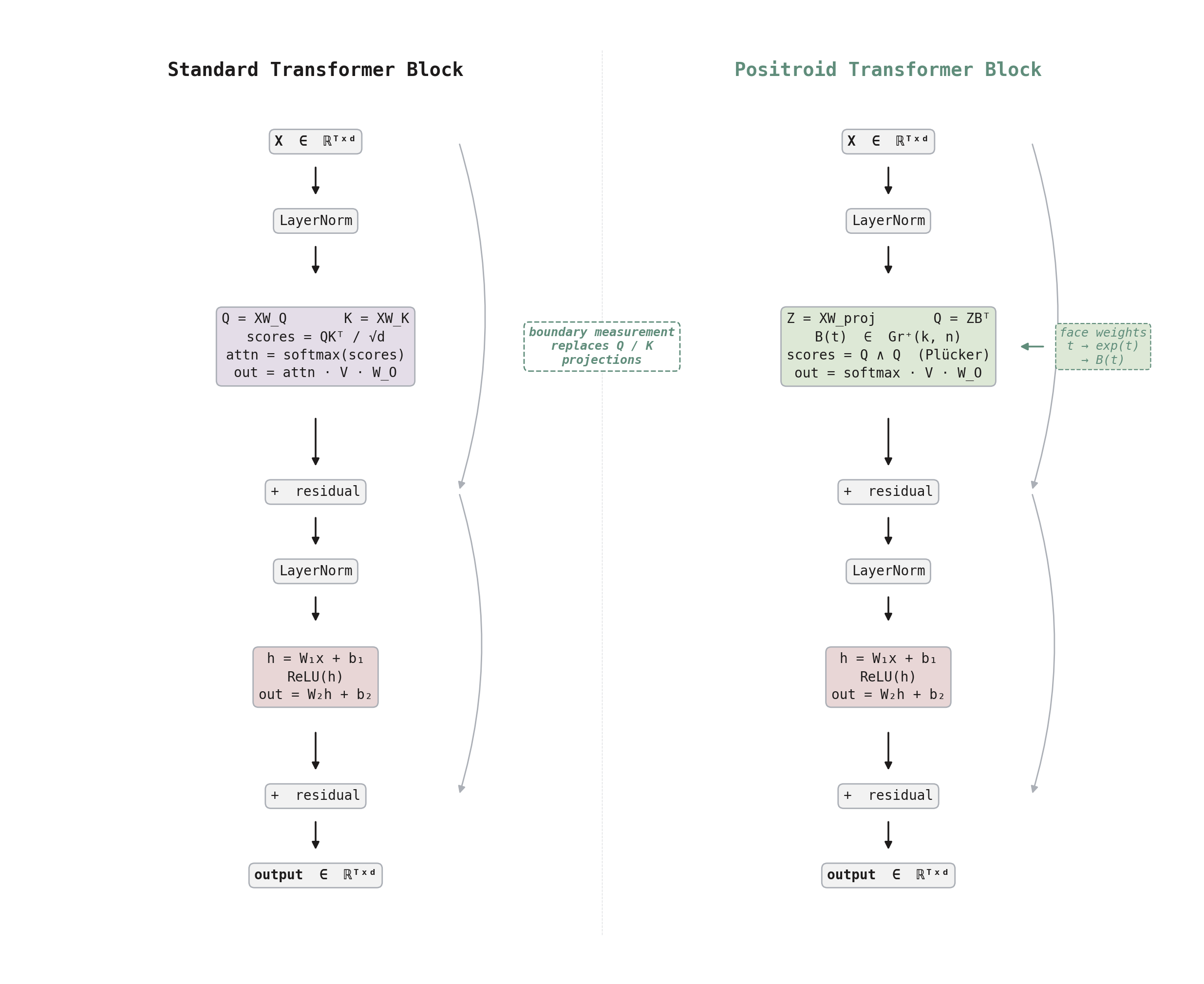
Figure 4. Standard vs positroid transformer block. The key difference is in the attention mechanism: standard attention uses separate Q and K projections with dot-product scoring, while positroid attention projects tokens through a boundary measurement matrix B(t) on Gr⁺(k,n) and computes Plücker coordinate scores. The MLP and residual structure are shared.
I tested both on a 10-class digit classification task (500 samples, PCA to 10 dimensions, \(d_\text{model} = 16\), 4 tokens, 2 layers). The results were encouraging:
| Mode | Attention | MLP | Test Accuracy | Params |
|---|---|---|---|---|
| Standard | QKV dot-product | ReLU (\(d_\text{ff}=64\)) | 90.7 ± 1.2% | 7370 |
| Positroid \(k=2\) | Boundary measurement | ReLU | 88.3 ± 3.3% | 6910 |
| Positroid + Tropical | Boundary measurement | Det + boundary | 82.3 ± 0.9% | 3422 |
Positroid attention alone was only 2.4pp behind standard. The tropical MLP used 54% fewer total parameters. At first glance, this looked like a genuine efficiency win.
But this was toy scale — a NumPy implementation on 500 data points. The real questions were whether the underlying conjectures held in existing models, and whether these components would survive careful ablation.
Testing GPT-2
Weights: not even close
I analyzed the weight matrices of GPT-2-small (117M parameters) across representative layers — \(W_Q, W_K, W_V, W_O\) for attention, \(W_\text{up}\) and \(W_\text{down}\) for the MLP.
Every matrix was full rank. The fraction of nonneg minors was 50% — exactly what you’d expect from a random Gaussian matrix. Fitting each weight matrix as a boundary measurement gave relative errors of 0.68 to 19.3.
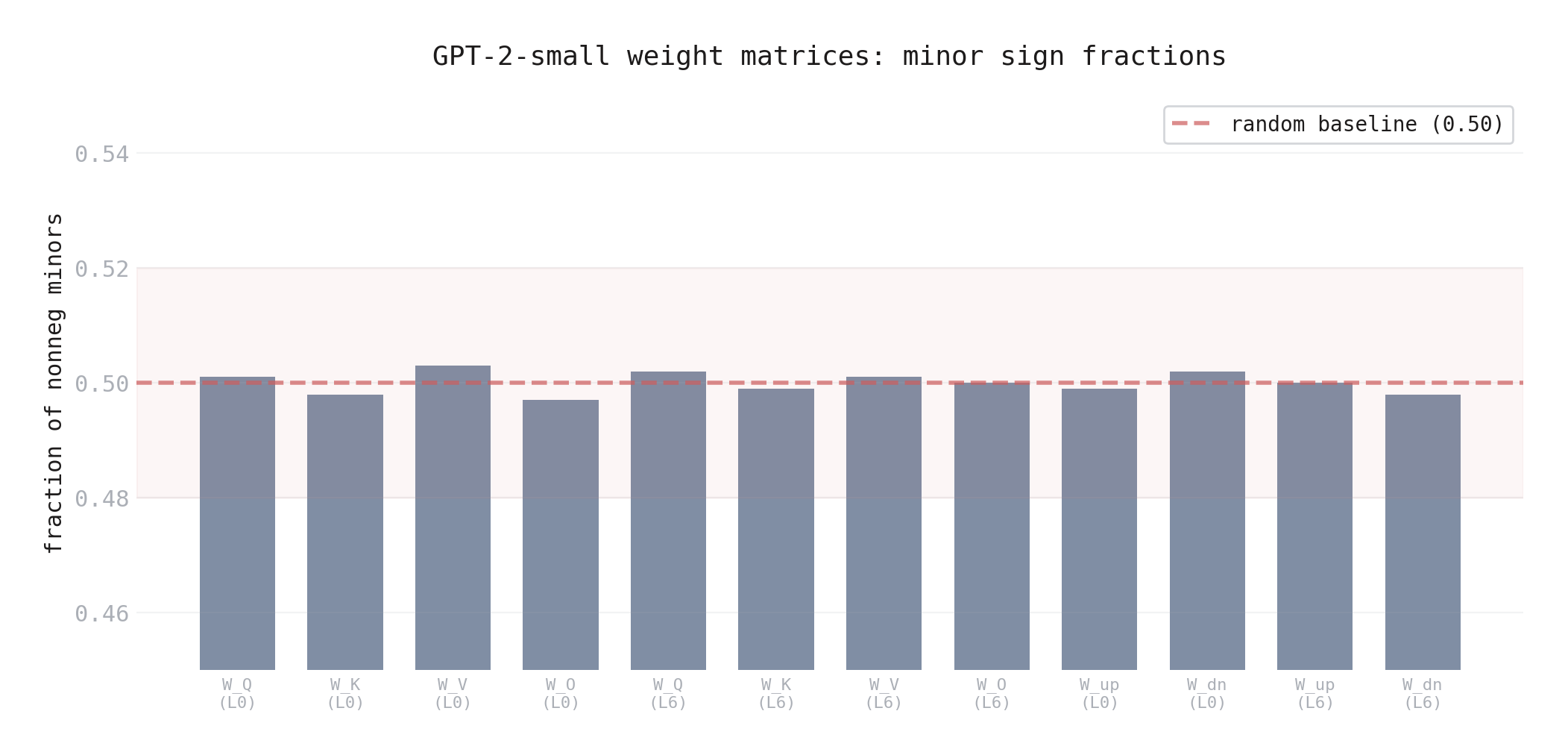
Figure 5. Fraction of nonneg minors across GPT-2-small weight matrices. Every matrix hovers at 0.50 — exactly what you’d expect from random Gaussian weights. The dashed line is the random baseline.
Prediction 1: falsified. GPT-2’s weights have zero positroid structure.
Attention patterns: a confound and a lesson
I extracted attention patterns from GPT-2 on WikiText data — 2,880 rectangular submatrices across all layers and heads.
The first run tested \(q = 3\) queries against \(n = 16\) keys. It showed an apparent +12 percentage point bias toward nonneg minors. For a few days, this looked like a genuine signal — but it turned out to be a confound.
About 20% of the submatrices were near-rank-deficient (mean rank 2.4 out of 3). Rank-deficient matrices have many near-zero minors — which are trivially nonneg — inflating the average. The signal was an artifact of rank deficiency, not geometric structure.
I reran at \(q = 2\), where rank deficiency is much less prevalent, and isolated the full-rank layers. Those had nonneg minor fractions of 0.48–0.54, compared to a random baseline of 0.503. Totally nonneg submatrices in the most decisive layer: 0 out of 240.
Prediction 2: falsified. Softmax attention does not produce positroid structure. The +12pp signal at q = 3 was a rank-deficiency artifact — a reminder that one parameter setting is never enough.
Why the Analogy Broke
So both predictions failed — weights and attention patterns show no positroid structure. But the failures aren’t random; they point to a specific reason the analogy between scattering amplitudes and transformers doesn’t hold.
The amplituhedron works for \(\mathcal{N} = 4\) super Yang-Mills because of structural properties the theory provides:
- Color ordering forces planarity and cyclic symmetry in external momenta
- Maximal supersymmetry constrains amplitudes to a single MHV degree \(k\)
- Total positivity of the external data matrix \(Z\) makes its image a positive geometry
Transformers have none of these. No cyclic ordering of tokens — skip connections and multi-head summation break any planar structure. No supersymmetry. No positivity constraint — weights are unconstrained real matrices optimized by SGD, which has no mechanism to enforce or prefer total nonnegativity.
The amplituhedron doesn’t “emerge” from computing scattering amplitudes — it’s built into \(\mathcal{N} = 4\) SYM via gauge symmetry. Expecting positroid structure to emerge from transformer training was hoping for structure without the mathematical scaffolding that produces it.
Ablating What Seemed to Work
With the discovery program ruled out, I turned back to the constructive results — the positroid components that seemed competitive at toy scale. The question was whether they held up under careful ablation.
A diagnostic run at 200 epochs confirmed that all modes — standard, positroid attention, and tropical — reach 100% train accuracy. The optimization gap from 50 epochs was just slower convergence, not a barrier. So any test accuracy gaps at 200 epochs are pure generalization failures, not training failures.
The tropical MLP: not what it seemed
I ran a five-way ablation, isolating the MLP comparison inside an otherwise identical transformer (same standard attention, same embedding, same output head). All non-standard MLPs were matched to ~670-800 MLP parameters. Results at 50 epochs (all five modes) and 200 epochs (three key modes):
| MLP Variant | Test Acc (50 ep) | Test Acc (200 ep) |
|---|---|---|
| Standard ReLU (\(d_\text{ff} = 64\)) | 89.7 ± 0.5% | — |
| Small ReLU (\(d_\text{ff} = 11\), matched params) | 87.0 ± 0.8% | 88.7 ± 0.5% |
| Unconstrained matrix + det | 85.3 ± 0.5% | 84.7 ± 1.2% |
| Fixed random matrix + det | 84.7 ± 1.7% | — |
| Boundary measurement + det (positroid) | 78.0 ± 1.6% | 77.3 ± 2.6% |
The ordering is the same at both timepoints, but the gaps widen with training — small ReLU improves while the det variants plateau or degrade. At 200 epochs:
- Positroid constraint hurts: -7.4pp vs unconstrained det. The boundary measurement eliminates matrices the network needs.
- Det worse than ReLU: -4.0pp at matched params. Even without the positroid constraint, the determinant nonlinearity underperforms ReLU.
- Learning the matrix barely matters: unconstrained det ≈ fixed random det at 50 epochs (+0.6pp). The encoding and readout layers do the work; the specific matrix geometry is irrelevant.
- The “54% param savings” was misleading: a ReLU MLP with \(d_\text{ff} = 11\) gets 88.7% at 200 epochs — that’s 11.4pp better than the tropical MLP that supposedly “saved” parameters.
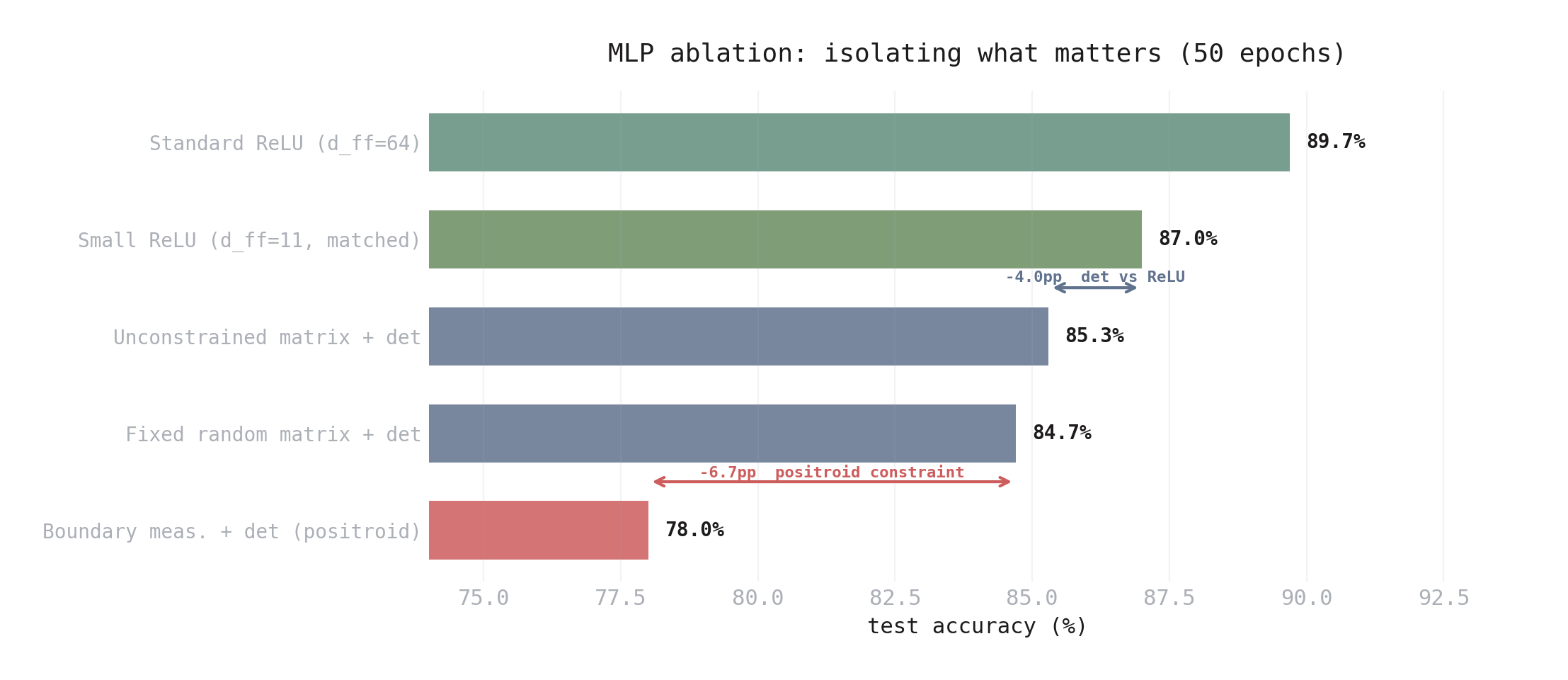
Figure 6. Five-way MLP ablation isolating the nonlinearity and constraint. The positroid boundary measurement (bottom) hurts by 7.4pp vs unconstrained det. The det nonlinearity itself loses 4.0pp vs matched-parameter ReLU.
Prediction 3: falsified. The geometric constraint adds nothing to MLPs. A smaller standard MLP achieves more with less complexity.
Positroid attention: competitive but unreliable
The attention story is more nuanced. I ran 5 trials at 200 epochs, isolating the attention comparison with standard MLP on both sides:
| Mode | Test Accuracy | Range |
|---|---|---|
| Standard | 89.6 ± 1.6% | 88–92% |
| Positroid \(k=2\) | 86.8 ± 4.7% | 80–93% |
The mean gap of 2.8pp is borderline acceptable. But the variance tells the real story. The five positroid trials split cleanly into two clusters:
- Good: 89%, 93%, 89% — competitive with or better than standard
- Bad: 80%, 83% — significantly worse
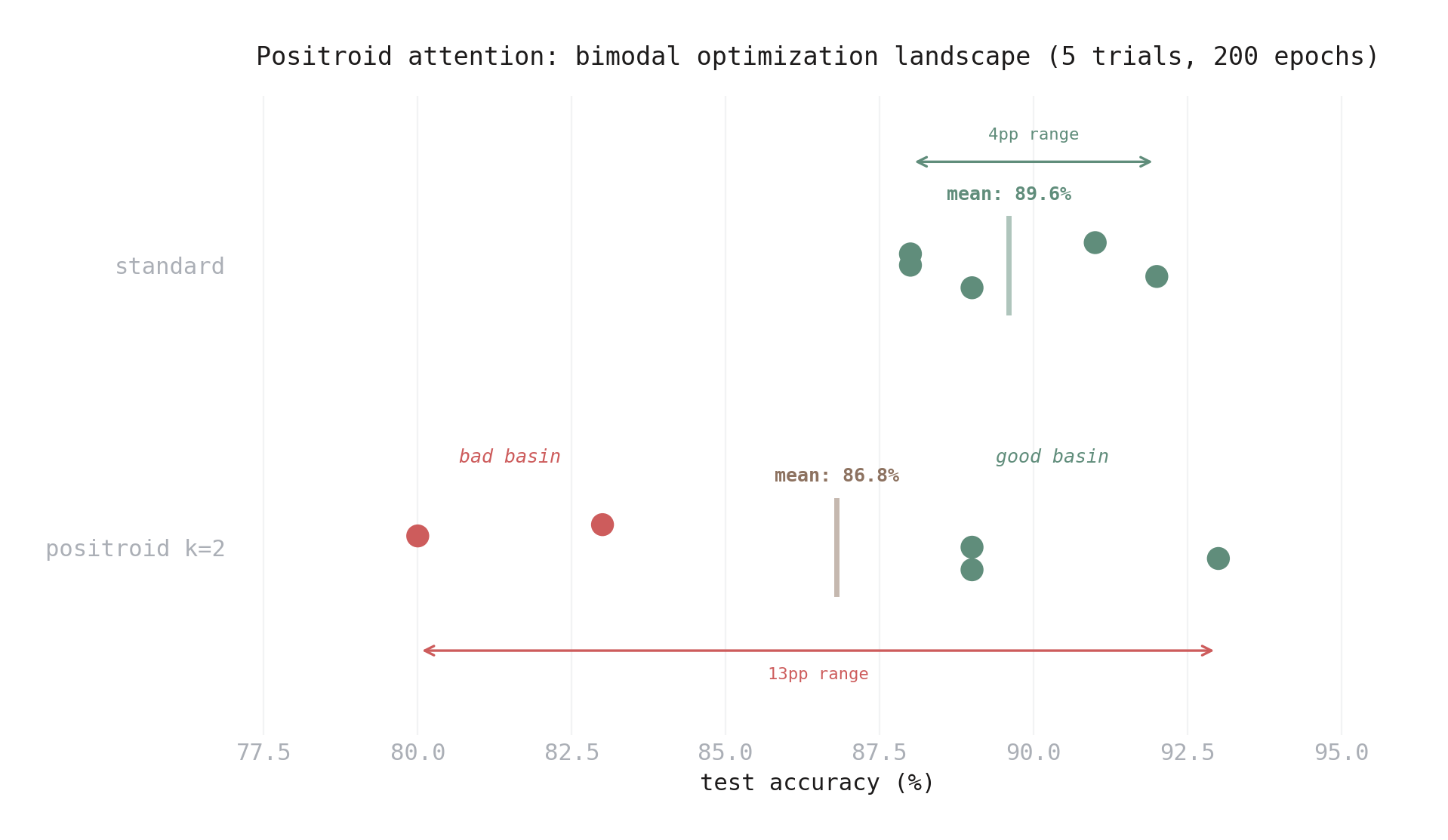
Figure 7. Individual trial accuracies for standard vs positroid attention (5 trials, 200 epochs). Standard trials cluster tightly (88–92%). Positroid trials split into two basins: three land near 89–93% (competitive), two fall to 80–83% (significantly worse).
This isn’t normal variation. It’s a bimodal optimization landscape: the boundary measurement parameterization has basins of attraction that either work or don’t. Standard attention shows no such bimodality — all 5 trials land in a tight 88–92% range.
Positroid attention is also 1.9x slower (189s vs 100s per trial) and saves only 460 parameters (6910 vs 7370) — a marginal 6% reduction that doesn’t justify the speed overhead or the coin-flip reliability.
Prediction 4: ambiguous. Competitive on average, but you wouldn’t trust a method that gives you 93% or 80% depending on initialization luck.
The Scorecard
| Prediction | Result |
|---|---|
| Weight matrices are approximately TP | Falsified — 50/50 minor signs, indistinguishable from random |
| Attention patterns are positroid | Falsified — apparent signal was rank-deficiency artifact |
| Positroid MLP constraint helps | Falsified — hurts by 7.4pp vs unconstrained |
| Det nonlinearity matches ReLU | Falsified — loses by 4.0pp at matched params |
| Positroid attention is competitive | Ambiguous — 2.8pp gap, bimodal, unreliable |
The hypothesis, as originally stated, didn’t hold up. Existing transformers don’t have positroid structure, and imposing it doesn’t help — with the possible exception of attention, where the results are mixed.
What Survived
The matroid pruning result stands. Single-layer TP networks have positroid matroids, the contiguous-implies-positroid theorem is proven, and matroid-guided pruning works. Nothing in the transformer experiments contradicts this — these are facts about single-layer geometry, and they remain true.
Tropical geometry remains real mathematics. ReLU networks are tropical rational functions (Zhang-Naitzat-Lim 2018). Softmax converges to tropical matrix products in the high-confidence limit (Alpay-Senturk 2026). These are theorems. They’re useful for analyzing neural networks even though they don’t yield practical architecture improvements.
Small standard MLPs work surprisingly well. One incidental finding: a standard ReLU MLP with \(d_\text{ff} = 11\) — instead of the typical 4x expansion to \(d_\text{ff} = 64\) — achieves 87.0% at 50 epochs and 88.7% at 200, only 1–2.7pp behind the full-size version at 47% fewer total parameters. The standard MLP expansion ratio is likely larger than necessary for many tasks. This has nothing to do with positroids, but it fell out of the ablation for free.
What I Learned
The analogy needed more scrutiny. “Scattering amplitudes have positroid structure, therefore neural networks should too” is a compelling starting point, but the structural prerequisites — cyclic ordering, supersymmetry, positivity of external data — don’t transfer automatically. The mathematical tools from one domain can still inform another, but you have to earn the connection rather than assume it.
“Discovery” and “design” are different questions. I conflated “Do existing transformers have this structure?” with “Is this structure useful for building transformers?” The first doesn’t imply the second (ResNets aren’t biological), and the second doesn’t require the first. Keeping these separate from the start would have sharpened the experiments.
Ablate before you scale. The tropical MLP’s “54% parameter savings” looked like a result worth porting to JAX. A five-variant ablation at toy scale resolved the question in an afternoon. That’s a good trade — better to learn cheaply than invest in a port first.
Check confounds at multiple settings. The +12pp minor bias at \(q = 3\) looked real for days. A single rerun at \(q = 2\) — controlling for rank deficiency — clarified it in minutes. One parameter setting is never enough.
Negative results clarify the landscape. Each falsification narrowed the search space. Knowing that GPT-2 weights aren’t TP, that the det nonlinearity loses to ReLU, that the boundary measurement constraint hurts MLP generalization — these sharpen the picture of where geometric structure can and can’t help.
For the pruning result that started this line of inquiry, see the previous post. For the mathematical background on positroid structure and the contiguous-implies-positroid theorem, see the companion post.