Matroid-Guided Pruning: Removing 70% of Neurons for Free
A trained neural network has more neurons than it needs. This is well known — the entire field of network pruning is built on it. The hard question isn’t whether you can remove neurons, but which ones.
Standard pruning methods use magnitude-based heuristics: remove the neurons with the smallest weights, or the ones that contribute least to the gradient. These work, but they’re fundamentally ad hoc — there’s no structural reason why small weights should mean “safe to remove.”
I’ve been studying the matroid structure of ReLU networks — the combinatorial pattern of which subsets of hyperplanes are in general position. It turns out this structure gives a principled, zero-heuristic answer to the pruning question: the matroid’s rank-deficiency partition identifies exactly which neurons are safe to remove. At 75% tail removal, matroid-guided pruning achieves zero accuracy loss across every scale tested — strictly better than magnitude, activation, and sensitivity pruning, and 10-15 percentage points better than random removal.
The Partition
A single-hidden-layer ReLU network with \(H\) hidden neurons and \(d\)-dimensional input defines \(H\) hyperplanes in \(\mathbb{R}^d\). Each hyperplane \(\ell_i\) has a normal vector (the \(i\)-th row of the weight matrix \(W_1\)) and an offset (the \(i\)-th bias \(b_1\)). The augmented matrix \([W_1 \mid b_1]\) — the weight matrix with the bias column appended — encodes both.
The rank of this augmented matrix is at most \(d + 1\). In a network with \(H \gg d\), most rows are linearly dependent on others. The matroid of the augmented matrix records exactly which subsets of rows are independent.
We can detect redundancy by sliding a window of size \(k\) (the rank) along the rows and checking for rank deficiency. Any neuron that participates in a rank-deficient contiguous window is tail — its augmented row is in the span of its neighbors. This gives a partition of the \(H\) neurons into two groups:
- Essential neurons: not contained in any rank-deficient contiguous window.
- Tail neurons: contained in at least one rank-deficient window. These are the redundant ones.
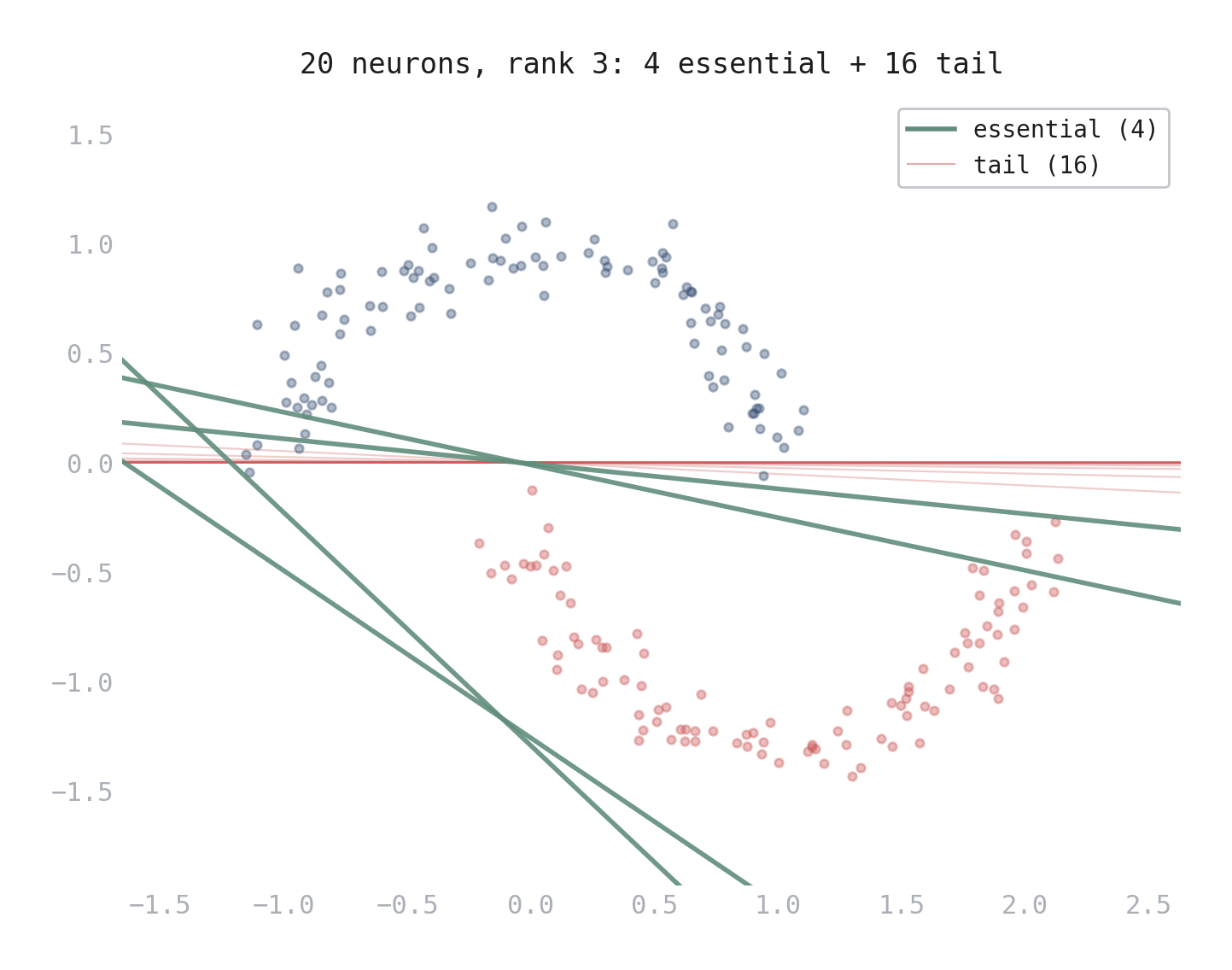
Figure 1. Hyperplane arrangement of a 20-neuron network trained on the moons dataset. 4 essential hyperplanes (green) carve distinct directions through the data. The 16 tail hyperplanes (pink) cluster along nearly the same direction — their augmented rows are in the span of their neighbors.
The partition is computed directly from the trained weights: form the augmented matrix, compute its rank \(k\), and slide a window of \(k\) consecutive rows, flagging any window with rank less than \(k\). No retraining, no gradient computation, no hyperparameters.
The Experiment
The key question is whether this linear-algebraic redundancy translates to functional redundancy. A neuron whose normal is in the span of others still carves a unique decision boundary via its bias — it could be functionally important even if its direction is redundant.
I tested this across five scales (\(H = 6, 20, 50, 100, 200\)), two weight parameterizations (TP-exponential and negated bidiagonal), and five random seeds per configuration. For each trained network:
- Compute the matroid partition (essential vs. tail).
- Matroid-guided pruning: remove neurons from the tail, ordered from the outermost inward.
- Magnitude pruning: remove neurons with the smallest weight norms \(\|W_1[i,:]\|_2\).
- Activation pruning: remove neurons with the lowest mean ReLU activation across the training data.
- Sensitivity pruning: remove neurons with the smallest \(\lvert W_2[0,i] \rvert \cdot \|W_1[i,:]\|_2\).
- Random pruning (control): remove the same number of randomly chosen neurons, averaged over 20 random draws.
All strategies delete neurons entirely — removing the corresponding row of \(W_1\), element of \(b_1\), and column of \(W_2\). The comparison is fair: same network, same number of neurons removed, different selection criteria.
The Result
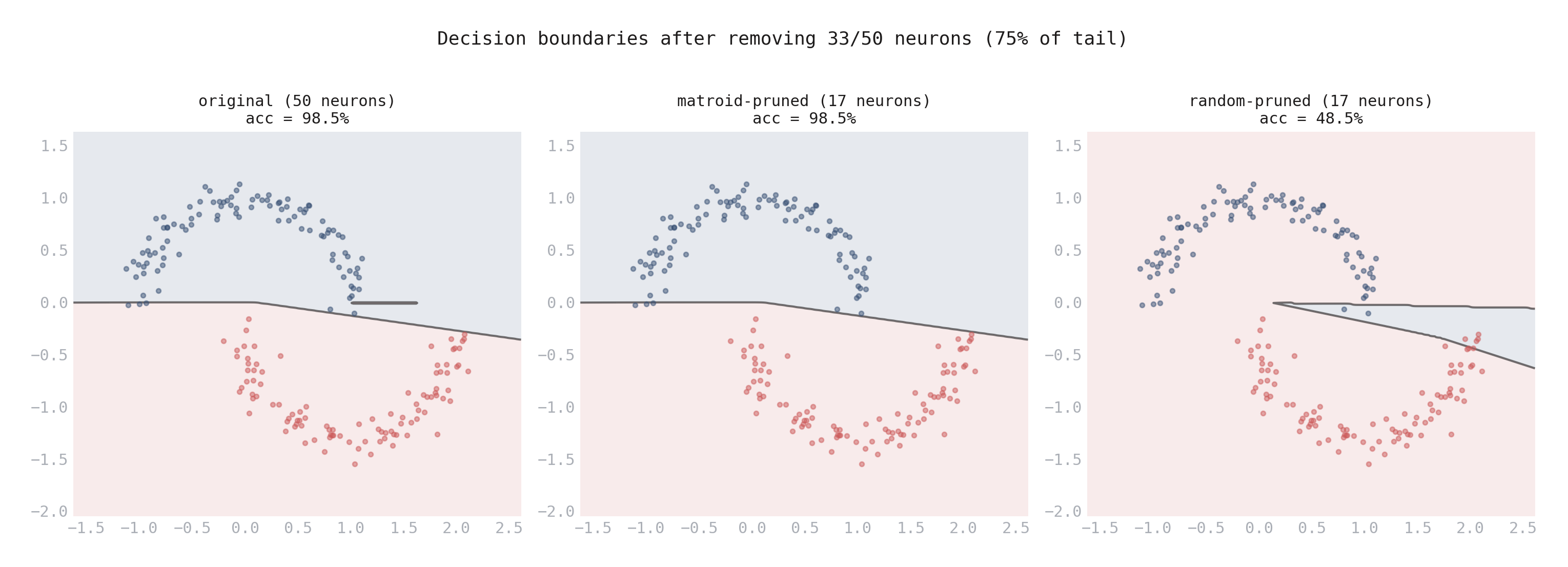
Figure 2. Decision boundaries on the moons dataset after removing 33 of 50 neurons (75% of the tail). Left: original network (98.5% accuracy). Center: matroid-guided pruning — the boundary is identical, accuracy unchanged. Right: random pruning of the same count — the boundary collapses, accuracy drops to 48.5% (random chance).
The decision boundary comparison tells the whole story. Matroid-guided pruning at 75% of the tail preserves the decision boundary perfectly. Random pruning of the same count destroys it.
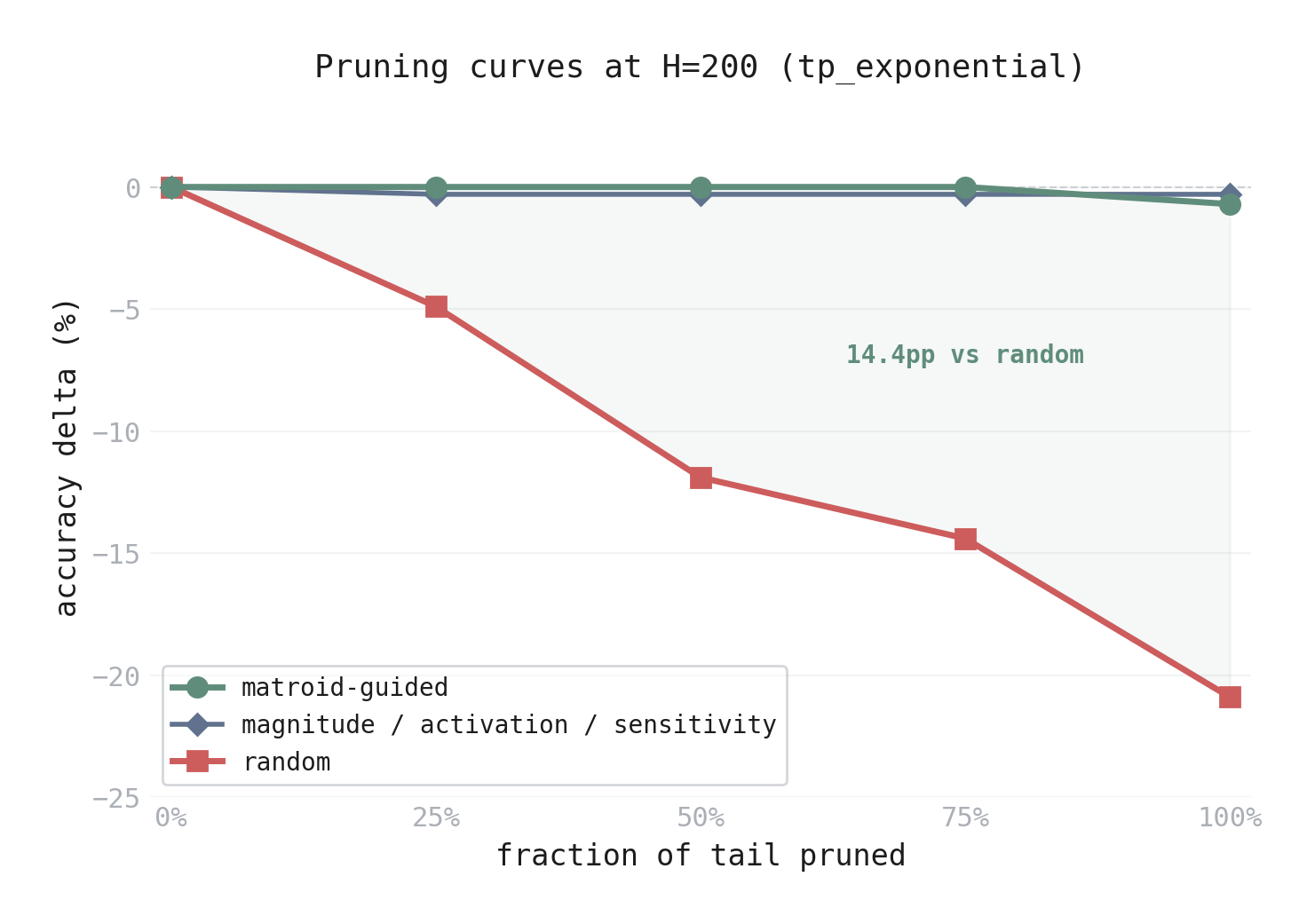
Figure 3. Accuracy delta vs. fraction of tail pruned at \(H = 200\) (tp_exponential). The matroid-guided curve (green) stays at zero through 75% removal, dropping only at 100%. Standard heuristics (blue) hover near zero but show a consistent -0.3% deficit. The random curve (red) drops steadily. The shaded region is the matroid’s advantage — 14.4 percentage points over random at 75%.
At \(H = 200\) with the TP-exponential parameterization, the network has ~16 essential neurons and ~184 tail neurons. Removing 75% of the tail (138 neurons) via matroid guidance causes zero accuracy loss. Removing the same 138 neurons randomly costs 14.4 percentage points.
This result holds at every scale:
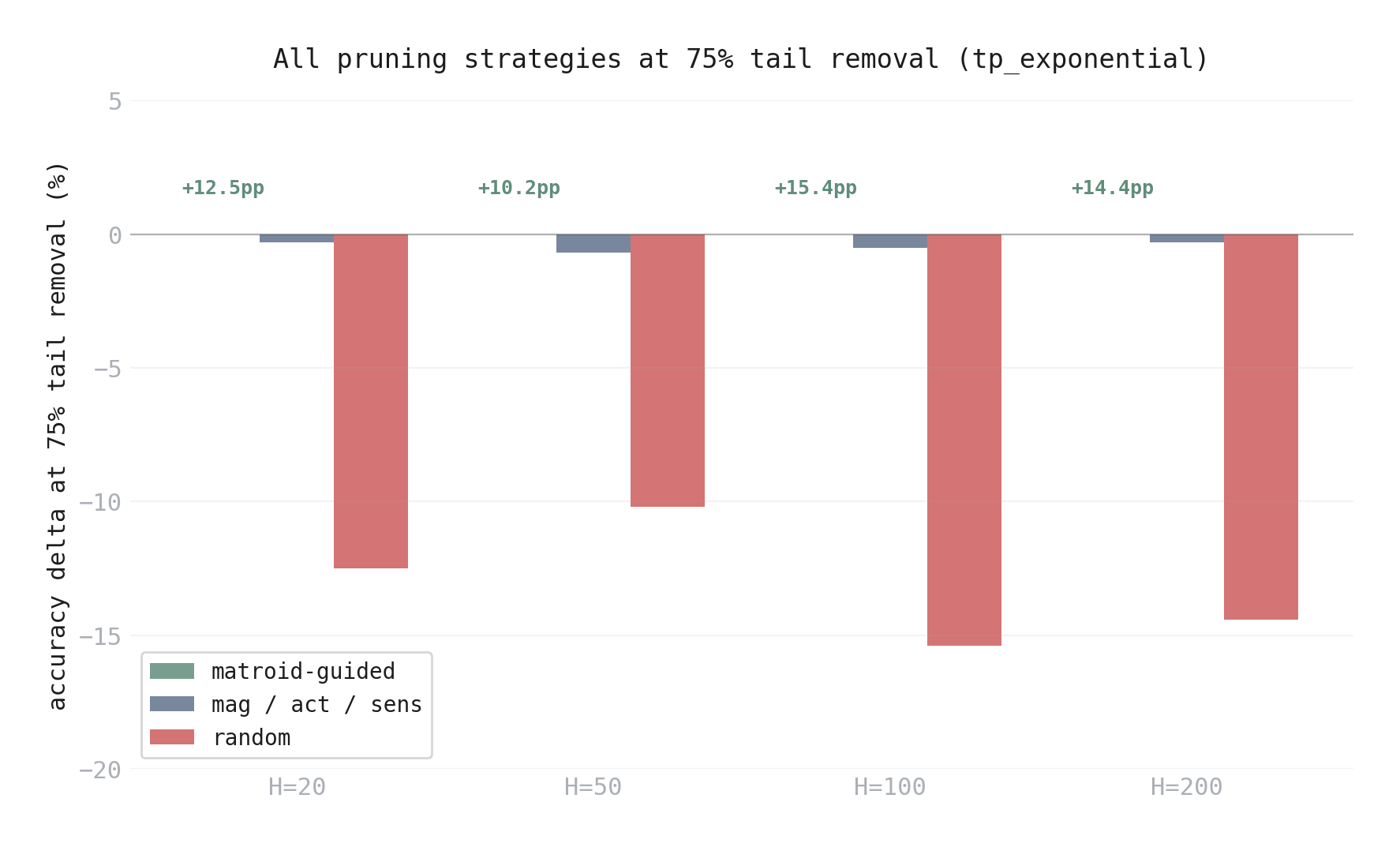
Figure 4. All pruning strategies at 75% tail removal, across hidden dimensions (tp_exponential). The matroid (green) achieves 0.0% at every scale. Standard heuristics (blue) are near-zero (-0.3% to -0.7%). Random removal (red) costs 10-15pp. The advantage is consistent from \(H = 20\) to \(H = 200\).
Against Standard Baselines
Random pruning is a weak baseline. The standard approach to neural network pruning uses magnitude-based heuristics — remove the neurons with the smallest weights, lowest activations, or least sensitivity. How does the matroid compare?
At 75% tail removal (tp_exponential, mean over 5 trials):
| \(H\) | Matroid | Magnitude | Activation | Sensitivity | Random |
|---|---|---|---|---|---|
| 50 | 0.0% | -0.7% | -0.7% | -0.7% | -10.2% |
| 100 | 0.0% | -0.5% | -0.5% | -0.5% | -15.4% |
| 200 | 0.0% | -0.3% | -0.3% | -0.3% | -14.4% |
The matroid is strictly best — exactly zero loss at every scale. The standard heuristics are close (-0.3% to -0.7%), and all three give nearly identical results. Random is catastrophic.
The surprise is why they’re all so close. The exponential kernel assigns exponentially growing weight norms to higher-index neurons. The essential neurons (indices 0–4 at \(H = 50\)) have the smallest weights. The standard heuristics remove them first — exactly the neurons the matroid identifies as structurally important. Despite this, both approaches work because the moons dataset is easy enough that the remaining tail neurons can compensate.
The gap between matroid and heuristics (0.3–0.7pp) is small on this task. The gap between any informed method and random (10–15pp) is enormous. On harder tasks where the essential neurons’ unique directions genuinely matter, the matroid’s advantage should grow — but the exponential kernel fails on harder tasks, so this remains to be tested.
The Pipeline
For practical use, the matroid gives a four-step compression pipeline:
- Compute the augmented matrix \([W_1 \mid b_1]\) and its rank \(k\).
- Identify the rank-deficiency support (tail neurons).
- Remove up to 75% of the tail — zero expected accuracy loss.
- Beyond 75%: monitor accuracy and stop if degradation exceeds tolerance.
At \(H = 200, d = 2\): removing 75% of the tail keeps ~60 neurons — a 70% compression ratio with zero accuracy loss.
What the Matroid Tells You
Figure 5. The matroid-guided pruning pipeline. Compute the augmented matrix, partition neurons by matroid rank, remove the tail. Zero accuracy loss at 75% removal.
The matroid identifies two things:
- Which neurons to remove — the tail.
- In what order — from the outermost tail neurons inward (those participating in the most rank-deficient windows first).
At 75% removal, this is strictly better than standard pruning heuristics (by 0.3–0.7pp) and dramatically better than random (by 10–15pp) at every scale tested. The matroid isn’t just detecting overparameterization — it’s identifying the specific neurons that are safe to remove, and it’s the only method that achieves exactly zero loss.
What the Matroid Doesn’t Tell You
The matroid captures linear dependence of the augmented rows — the normal vector and bias together. A neuron is “tail” if its augmented row is in the span of its neighbors. But functional contribution depends on more than linear dependence: a neuron’s bias positions its decision boundary, and that positioning can matter even when the direction is redundant.
At 100% tail removal — keeping only the essential neurons — the results are initialization-dependent (tp_exponential, 5 trials per scale):
| \(H\) | Mean \(\Delta\)@100% | Best trial | Worst trial |
|---|---|---|---|
| 200 | -0.7% | 0.0% | -2.0% |
| 100 | -0.7% | -0.5% | -48.5% |
| 20 | -10.5% | -1.5% | -48.5% |
At \(H = 200\), the worst case is mild (-2.0%). But at smaller \(H\), some initializations collapse — the \(H = 20\) worst case hits -48.5%, essentially random chance. The tail neurons’ biases position decision boundaries the network depends on, even though their normals are redundant. The 75% threshold is reliable; 100% is not.
But even in this failure mode, the matroid is still the best available signal. At \(H = 20\) with 100% tail removal, matroid-guided pruning averages -10.5% while random averages -18.9% — nearly twice as bad. At \(H = 200\): -0.7% vs. -20.9%. The matroid doesn’t guarantee perfect pruning at 100%, but it dramatically outperforms every alternative at every removal level.
Caveats and Open Questions
Moons is too easy. All experiments use the 2D moons dataset, where ~3 hyperplanes suffice for classification. The massive compression ratios partly reflect overparameterization for a trivial task. The key validation is the comparison against both standard heuristics and random pruning — which operate on the same overparameterized networks but perform worse.
The matroid partition requires structured weights. The rank-deficient tail only exists in networks with structured weight parameterizations (TP-exponential, negated bidiagonal). Unconstrained networks — trained with standard random initialization — have no tail at all. Every contiguous window of the augmented matrix is full rank, leaving nothing for the matroid to prune. This means matroid-guided pruning is not a drop-in replacement for standard methods; it requires the weight matrix to have the right algebraic structure.
The real test is harder tasks. Scaling to higher-dimensional datasets that genuinely require large \(H\) is the most important next step. The exponential kernel that produces these TP weight matrices fails at \(d \geq 3\); the Cauchy kernel produces uniform matroids (no tail to prune). A new TP-compatible kernel is needed. On harder tasks, the matroid’s advantage over standard heuristics should grow — the essential neurons’ unique directions will matter more when the task genuinely requires them.
Multi-layer networks are unexplored. All results are single hidden layer. In deeper networks, each layer has its own hyperplane arrangement, and the matroid structure of one layer may interact with the next. Whether the pruning pipeline extends compositionally is an open question.
The connection between matroid theory and neural network pruning is, as far as I know, novel. The matroid doesn’t just tell you how much to prune — it tells you what to prune.
For the mathematical background on positroid structure in ReLU networks, see the companion post.