The Hidden Geometry of ReLU Networks
Every ReLU neural network secretly draws lines through space. A single-hidden-layer network with \(H\) hidden neurons and \(d\)-dimensional input creates \(H\) hyperplanes — flat boundaries that slice the input space into regions. On each side of a hyperplane, a neuron is either “on” (positive) or “off” (clipped to zero). The network’s decision boundary is built from these cuts.
I’ve been studying the combinatorial structure of these hyperplane arrangements — specifically, which subsets of hyperplanes are in “general position” and which aren’t. The results were surprising: a natural conjecture held across 800+ training runs, was shattered by deliberate construction, and the failure revealed a clean mathematical pattern that I was able to prove as a theorem.
This post tells that story. For the full technical details including proofs, see the companion post.
Lines, Planes, and Independence
Think about drawing lines in 2D. Two random lines will cross at a single point — they’re independent. But two lines that happen to be parallel, or two copies of the same line, are dependent — they don’t carry as much geometric information as you’d expect from two lines.
Now consider three lines. If they all pass through the same point, they’re dependent in a specific way — any two of them are fine, but the triple has a coincidence. If no three meet at a point, all triples are independent.
This notion of “which subsets are independent?” is exactly what a matroid captures. A matroid is a combinatorial structure that records which subsets of a collection are independent, subject to some natural axioms (if a set is independent, so are all its subsets; if you have two independent sets of different sizes, you can extend the smaller one). Matroids show up all over mathematics — in linear algebra, graph theory, and geometry — because they abstract the common pattern underlying all of these.
For a ReLU network, the “collection” is the set of \(H\) hyperplanes from the hidden layer. The matroid records which subsets of hyperplanes are in general position (independent) and which have unexpected coincidences (dependent). The rank of the matroid is \(d + 1\) for a \(d\)-dimensional input — the maximum number of hyperplanes that can be mutually independent.
A subset of \(d + 1\) hyperplanes is called a basis if those hyperplanes are in general position. If they have a coincidence — if they all share a common point — that subset is a non-basis. The set of all bases completely determines the matroid.
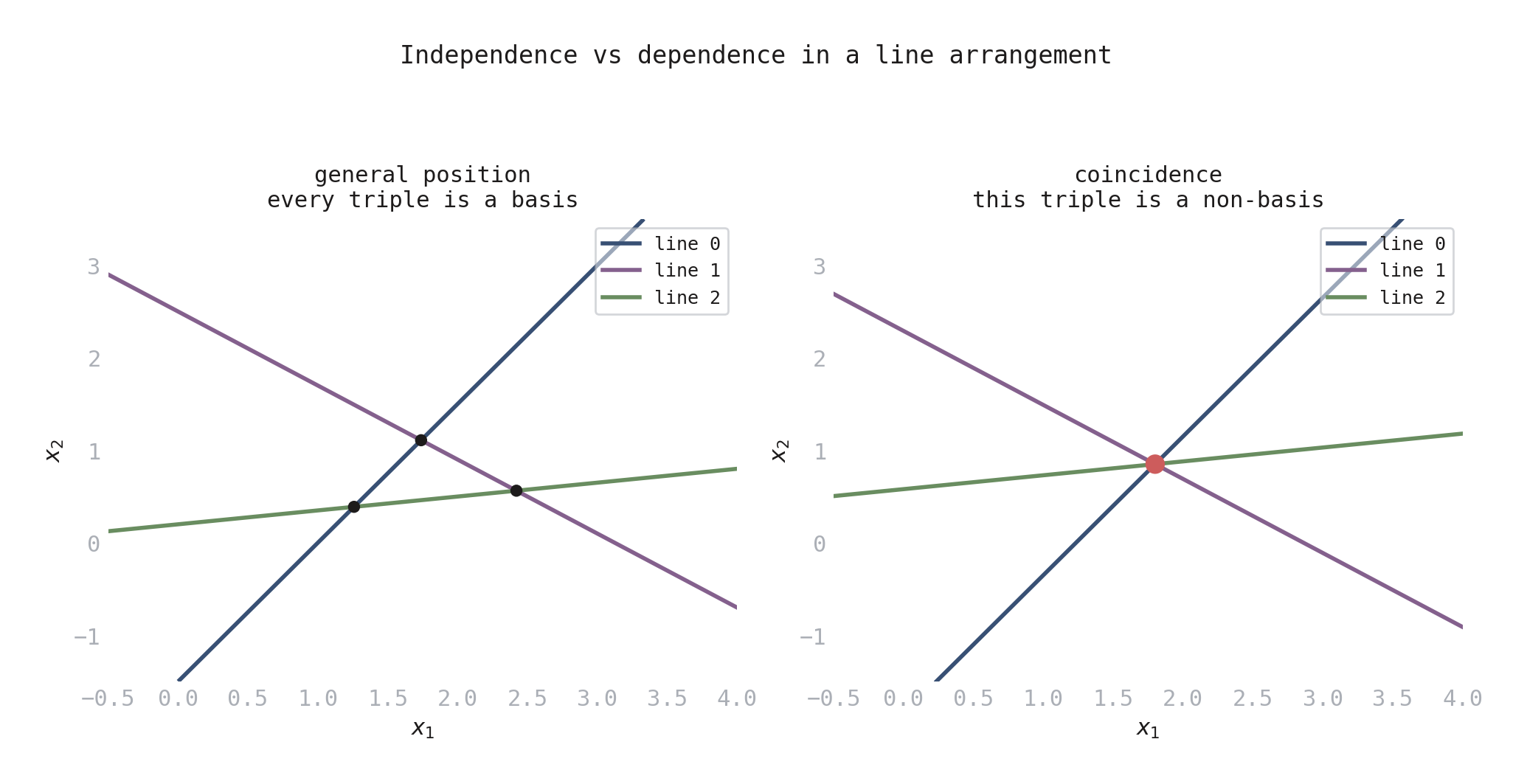
Figure 1. Three lines in 2D. Left: general position — the lines form a triangle, with each pair meeting at a different point. Every triple is a basis. Right: all three lines pass through the same point (red dot) — a coincidence. This triple is a non-basis.
Positroids: Matroids with Circular Symmetry
Not all matroids are created equal. Some have extra structure that makes them especially well-behaved.
Imagine placing the \(H\) hyperplane labels \(\{0, 1, \ldots, H-1\}\) around a circle, like hours on a clock. A positroid is a matroid whose combinatorial structure is compatible with this circular ordering in a precise sense. Positroids were discovered by Alexander Postnikov in his study of the totally nonnegative Grassmannian, a beautiful geometric object from algebraic geometry, and they turn out to have remarkably clean combinatorial descriptions.
The key property for us is that positroids are exactly the matroids that arise from totally positive (TP) matrices — matrices where every square submatrix has nonnegative determinant. TP matrices show up naturally in neural networks when you parameterize the weight matrix using kernels like:
\[W_{ij} = \exp(a_i \cdot b_j) \qquad \text{or} \qquad W_{ij} = \frac{1}{a_i + b_j}\]Both of these produce TP matrices by classical results. So the question becomes: if a ReLU network’s weight matrix is totally positive, does the resulting hyperplane arrangement always have positroid structure?
800 Trials: The Conjecture
I trained single-hidden-layer ReLU networks with TP-constrained weights across a range of configurations: multiple datasets, both kernel types, hidden dimensions from 4 to 16, and input dimensions from 2 to 5.
Over 800 trials, every matroid was a positroid. Zero counterexamples.
There was a caveat, though. Most trials produced uniform matroids — matroids where every subset of the right size is a basis, meaning all hyperplane subsets are in general position. A uniform matroid is automatically a positroid (there are no non-bases to violate anything), so most trials didn’t really test the conjecture.
Non-trivial positroids — ones with actual non-bases — appeared mainly with 2D input and the exponential kernel. There, up to half the trials produced matroids with rich structure: hundreds of bases, non-trivial dependency patterns. And every one was a positroid.
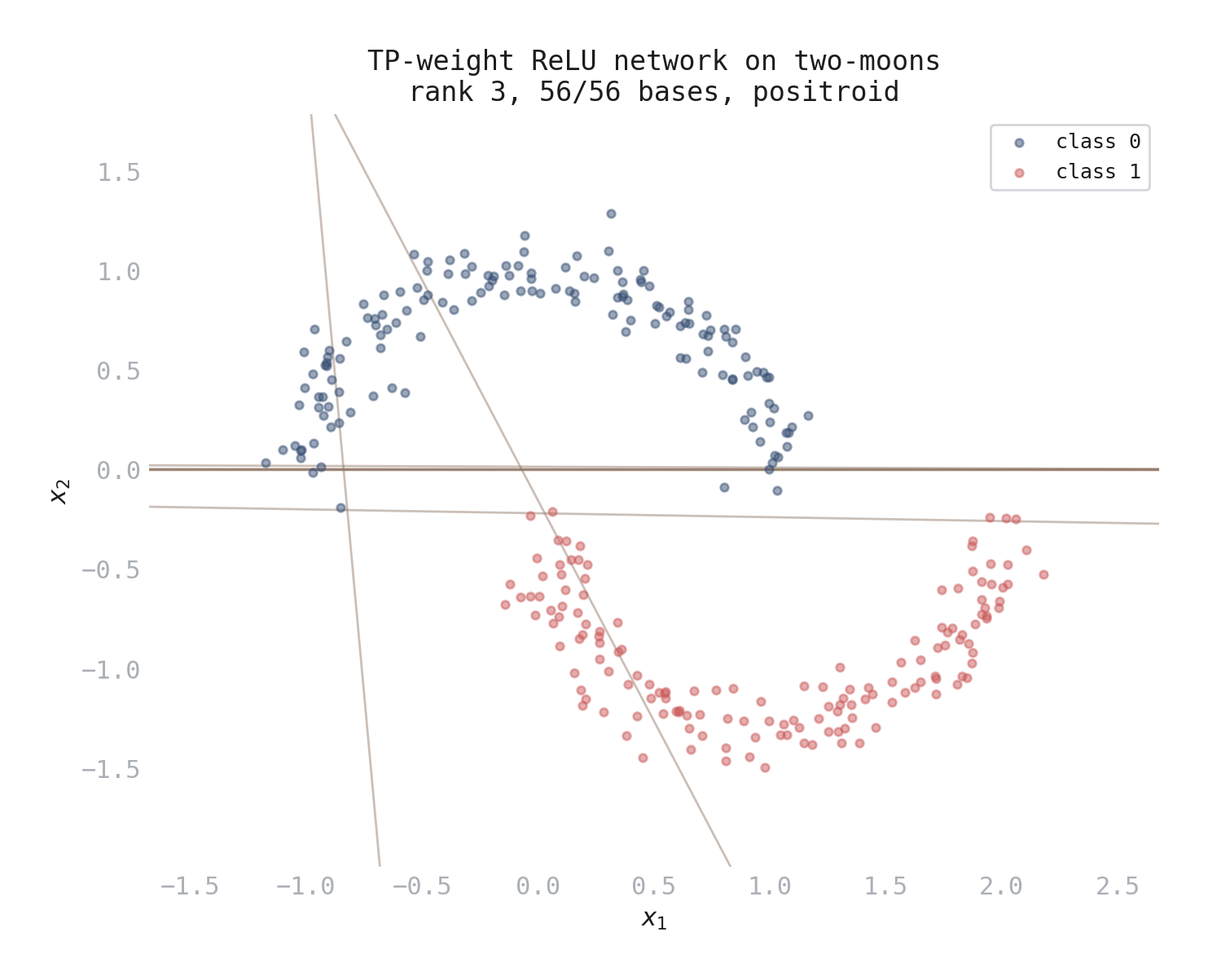
Figure 2. A TP-weight ReLU network trained on the two-moons dataset. The 8 lines are the hyperplanes from the hidden layer. Together they define a matroid of rank 3 on 8 elements. In this case every triple of lines is in general position (the matroid is uniform), so it’s trivially a positroid.
Breaking the Conjecture
Rather than run more training experiments, I decided to attack the conjecture directly.
The key insight is that a ReLU network’s hyperplane arrangement depends on both the weights (which determine the directions of the hyperplanes) and the biases (which determine their positions). Total positivity constrains the weights, but places no constraint on the biases. The biases are free parameters.
Making a specific subset of hyperplanes dependent requires satisfying just one linear equation on the biases for that subset. This is easy to do by construction.
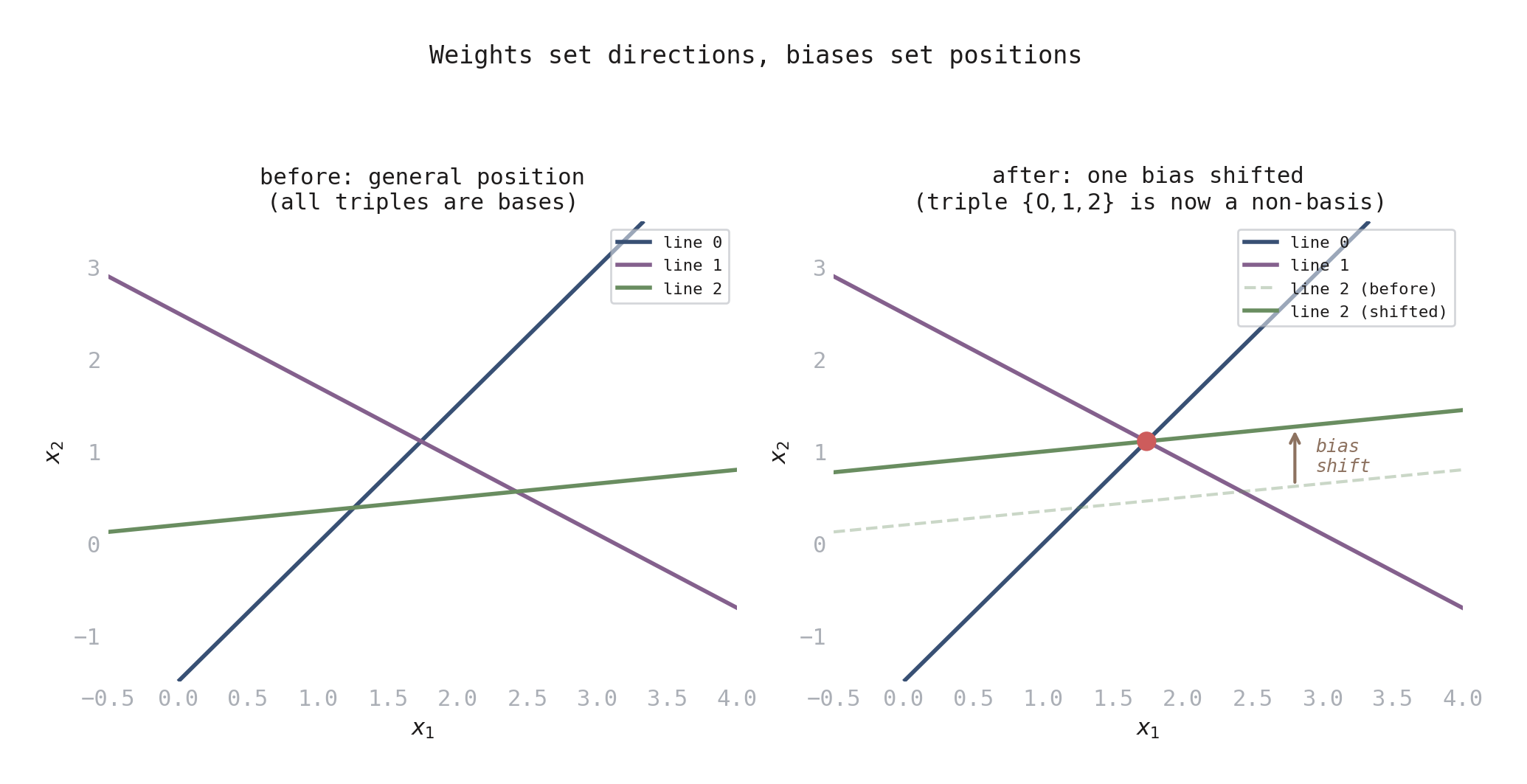
Figure 3. How biases create dependencies. Left: three lines in general position — all triples are bases. Right: the same line directions (same weights), but line 2 shifted upward (bias changed) so all three meet at one point (red dot). One linear equation on the biases is all it takes.
I ran 16,820 targeted trials: pick a TP weight matrix, then deliberately choose biases to create specific dependency patterns. The result: 12,642 counterexamples. The conjecture is false.
The smallest counterexample has just 5 hyperplanes in 2D. Pick any TP weight matrix and choose biases so that hyperplanes \(\{0, 2, 4\}\) — the 1st, 3rd, and 5th — are dependent. The resulting matroid (9 out of 10 possible bases) is not a positroid.
But the counterexamples had a pattern. Every one involved making a spread subset dependent — a subset whose elements have gaps when arranged around the circle. When I tried making contiguous subsets dependent — subsets that form an unbroken arc on the circle — the matroid was always a positroid.
Contiguous vs Spread: The Pattern
This is the crucial distinction. Arrange the hyperplane labels \(\{0, 1, \ldots, H-1\}\) around a circle. A subset is a cyclic interval if its elements form a contiguous arc — like \(\{2, 3, 4\}\) on a clock. A subset is spread if there are gaps — like \(\{0, 2, 4\}\).
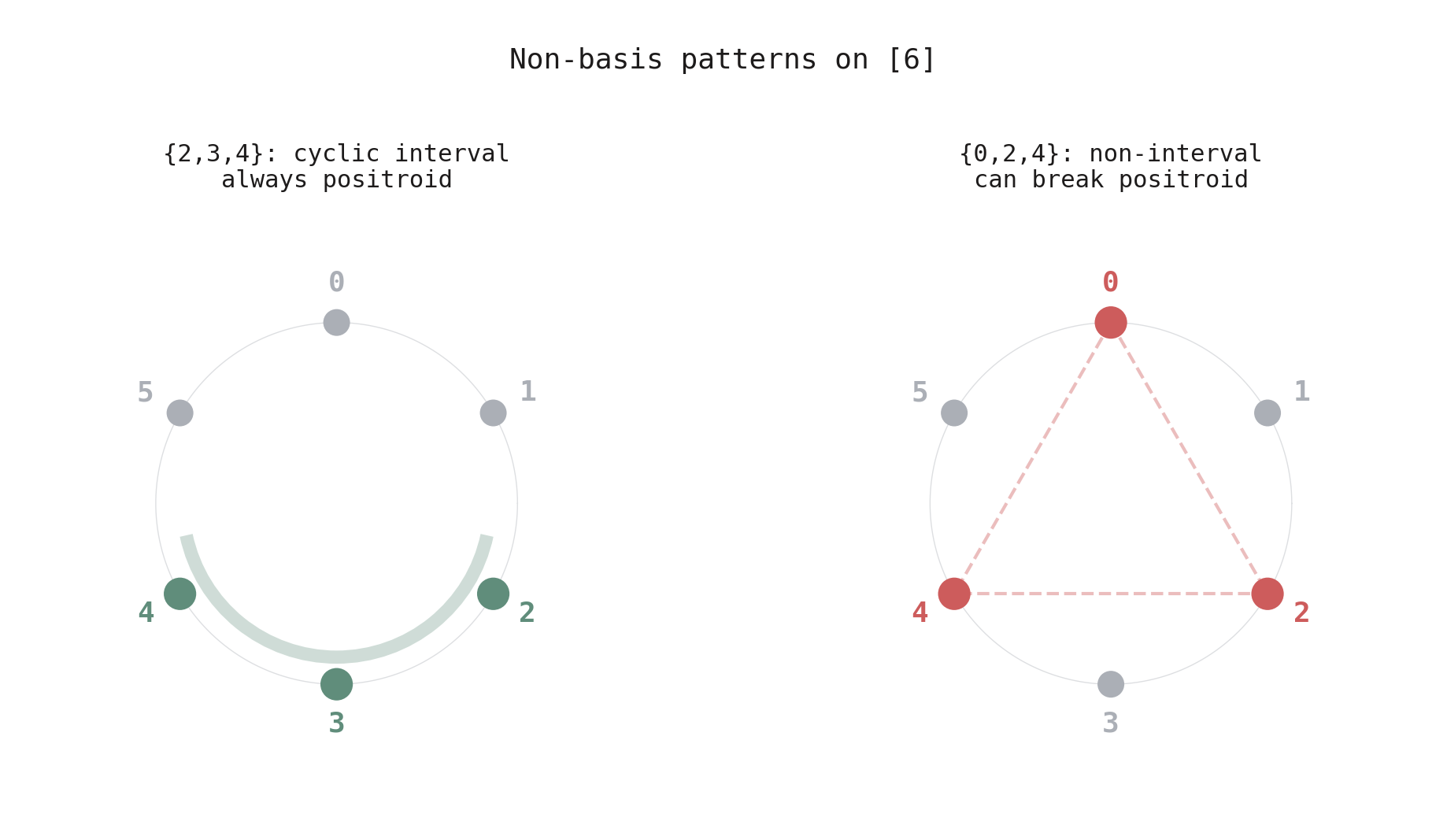
Figure 4. The two types of non-basis on a circle of 6 elements. Left: \(\{2,3,4\}\) is a cyclic interval — contiguous on the circle. Making it a non-basis preserves the positroid property. Right: \(\{0,2,4\}\) is spread — gaps between the elements. Making it a non-basis can break the positroid property.
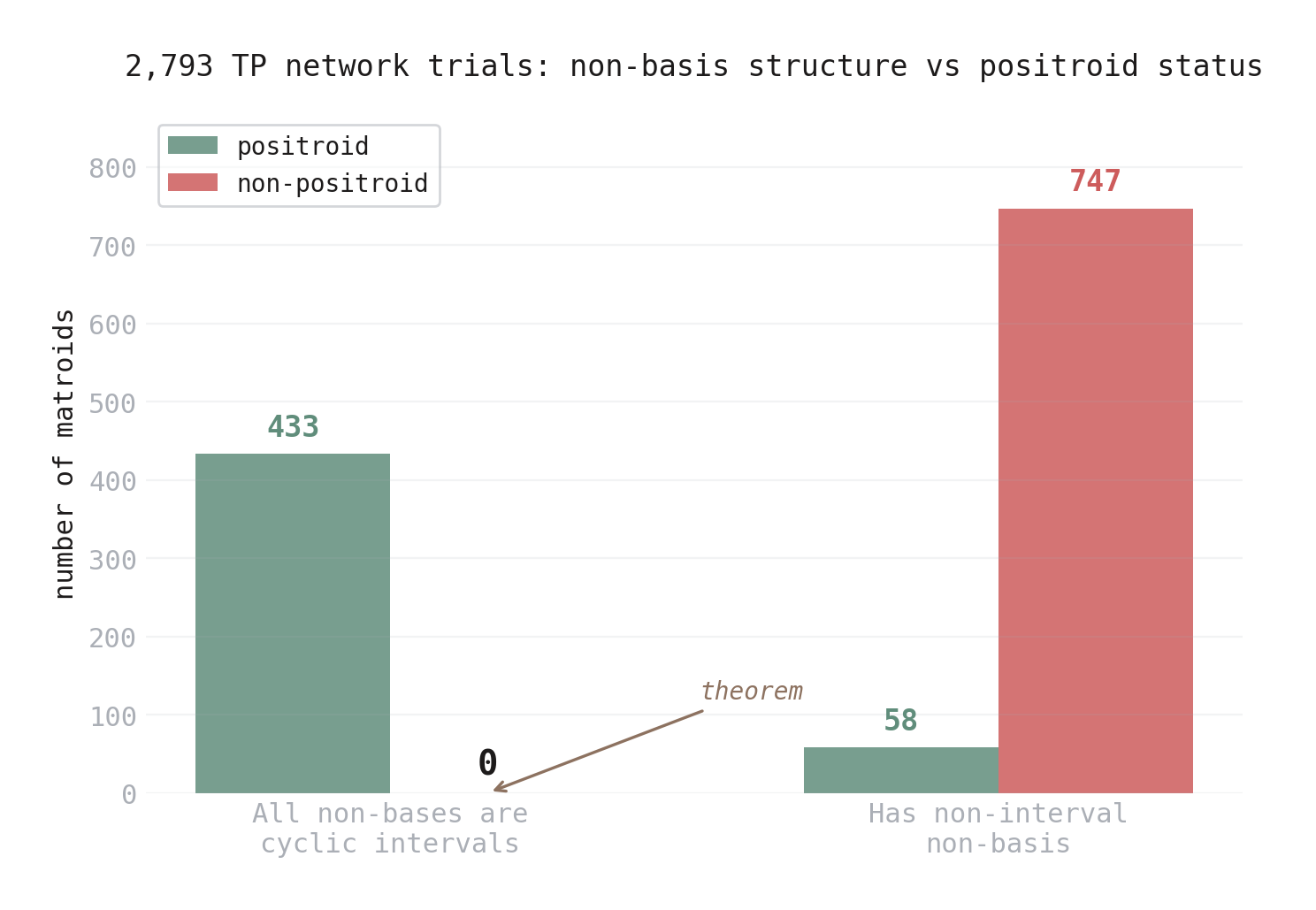
Figure 5. Results from 2,793 TP network trials, classified by non-basis structure. Left: when all non-bases are cyclic intervals, the matroid is always a positroid (433 out of 433). Right: when any non-basis is spread, the matroid is usually not a positroid (747 out of 805).
The dichotomy is sharp. Across 2,793 trials:
- All non-bases are cyclic intervals: 433 positroids, 0 non-positroids.
- Some non-basis is spread: 58 positroids, 747 non-positroids.
And here’s the punchline: across all 800+ training trials, gradient descent only ever produced cyclic-interval non-basis patterns. It never created a spread dependency. The original conjecture held for trained networks — not because of any algebraic property of TP matrices, but because training dynamics avoid the “bad” patterns.
The Theorem
The zero in the left column of Figure 5 isn’t a coincidence. It’s a theorem.
Theorem. If every non-basis of a matroid is a cyclic interval, then the matroid is a positroid.
The intuition is this: a cyclic interval like \(\{j, j+1, \ldots, j+k-1\}\) is, in a precise sense, the “first \(k\) elements” when you start counting from position \(j\) around the circle. Positroids are characterized by a reconstruction procedure that builds the matroid by looking at the first basis in each of \(n\) cyclic orderings. When a non-basis is a cyclic interval, it’s exactly the set that this reconstruction procedure checks first at one of its starting positions — and because it’s not a basis, the procedure correctly excludes it. But when a non-basis is spread, it can slip through the reconstruction filter at every starting position, creating an inconsistency that breaks the positroid property.
(The full proof uses the Grassmann necklace characterization of positroids. See the technical post for details.)
There’s also a clean if-and-only-if for the simplest case:
Corollary. Start with the uniform matroid (every subset is a basis) and remove a single subset. The result is a positroid if and only if that subset is a cyclic interval.
This was verified exhaustively for all parameters up to \(n = 9\).
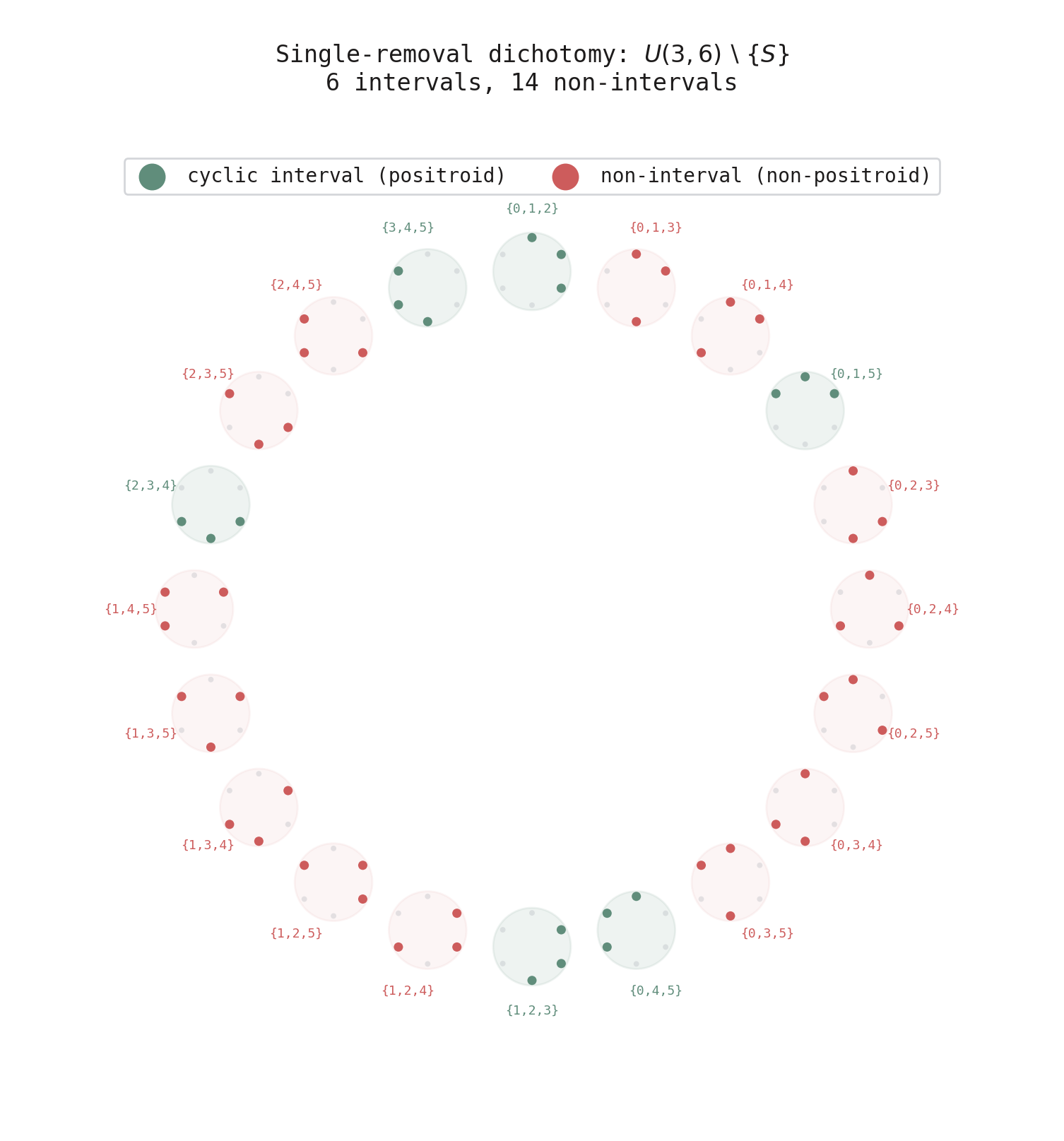
Figure 6. All 20 three-element subsets of \([6]\), each shown as a mini-circle. Green: cyclic intervals — removing them from the uniform matroid gives a positroid. Red: non-intervals — removing them gives a non-positroid. The corollary says this split is exact.
What This Means
The original conjecture — TP weights imply positroid structure — is false. But something more interesting is true: training dynamics on TP-weight networks only produce positroid matroids, and the theorem explains why. The non-basis patterns that would break positroid structure (spread dependencies) are precisely the ones that gradient descent never creates.
This shifts the question from algebra to dynamics. The revised conjecture is:
For TP-weight networks trained by gradient descent on binary classification, the affine matroid is always a positroid — because training only produces cyclic-interval non-basis patterns.
If true, this connects positroid combinatorics to the implicit bias of gradient descent, a central topic in deep learning theory. Gradient descent is known to favor certain solutions over others (low-rank matrices, max-margin classifiers). The claim here is that it also favors solutions with clean combinatorial geometry.
Open Questions
Does TP structure matter? If unconstrained (non-TP) trained networks also produce only positroids, then the phenomenon is entirely about training dynamics. If unconstrained networks sometimes produce non-positroids, then TP structure and training dynamics are jointly responsible — the most interesting case.
Why does training avoid spread patterns? There should be a geometric reason why gradient flow on the TP manifold only creates contiguous dependency patterns. Understanding this could reveal new structural properties of trained networks.
What happens with deeper networks? All experiments used single-hidden-layer networks. Multi-layer networks compose multiple hyperplane arrangements, and the interaction between layers could produce richer matroid structure.
Update: TP Structure Matters (2026-03-04)
The theorem explains why contiguous non-basis patterns always give positroids. But it raises a new question: is the TP constraint actually doing the work, or would any trained network produce only contiguous patterns? If unconstrained networks also avoid spread dependencies, the phenomenon is purely about gradient descent and TP structure is a red herring. If they don’t, then TP structure and training dynamics are jointly responsible — the most interesting case.
The answer is now in: TP structure matters.
I designed a non-TP weight parameterization called negated bidiagonal that preserves the key property making exponential networks produce non-trivial matroids (hyperplane normals that converge during training) while breaking total positivity. The construction is: take the usual TP exponential matrix, then multiply it by a bidiagonal matrix with alternating \(\pm\) signs on the subdiagonal. This scrambles the row ordering just enough to break TP while preserving the training dynamics that create near-collinear normals.
The result: over 60 training runs on the moons dataset, negated bidiagonal networks produced 2 non-positroid matroids (~3%). TP exponential networks produced zero over the same 60 runs. Both modes create non-uniform matroids at similar rates (~22-25%), so the comparison is fair — the difference is purely about whether the non-bases have positroid structure.
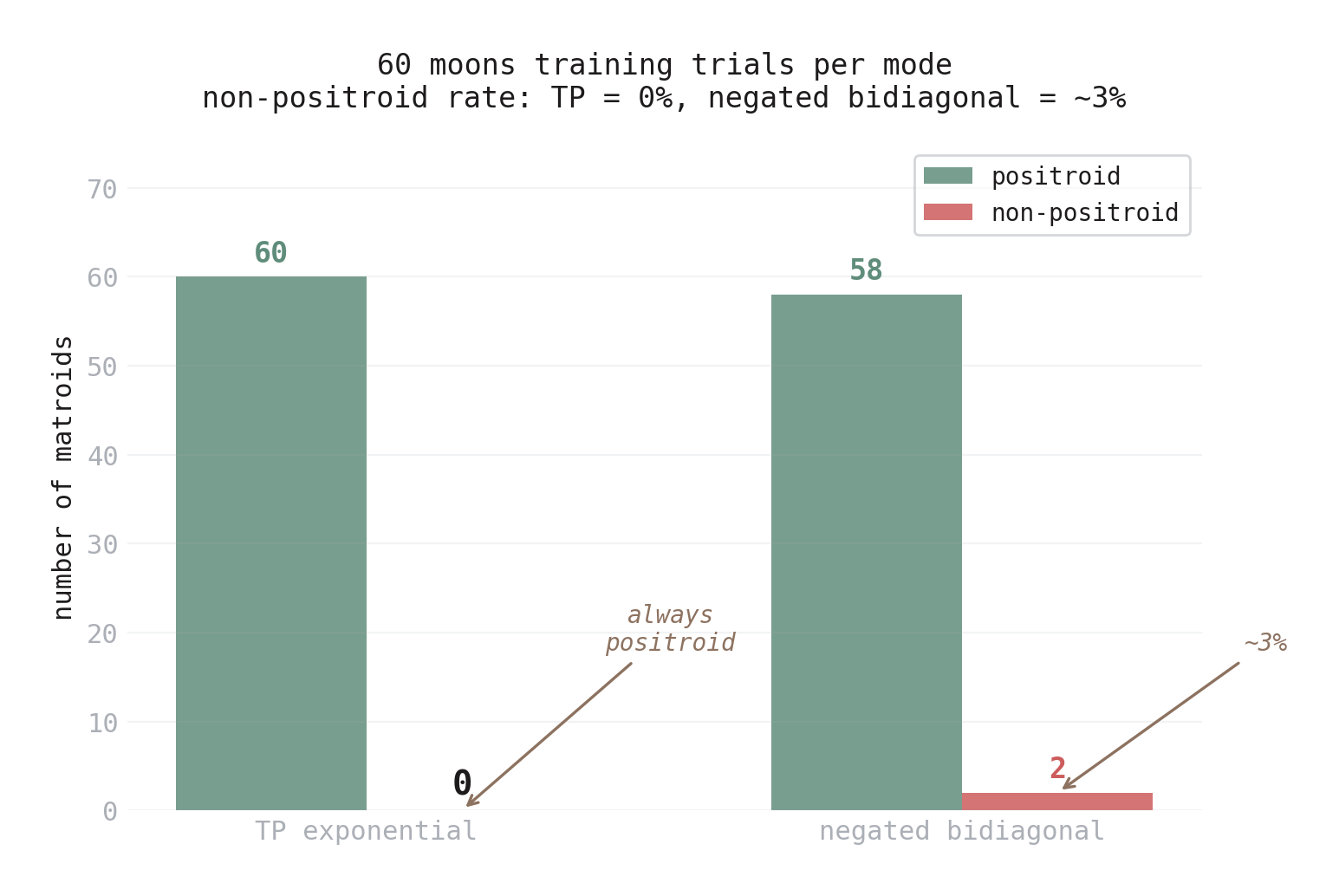
Figure 7. Non-positroid rates from 60 moons training trials per mode. TP exponential: zero non-positroids. Negated bidiagonal: 2 non-positroids (~3%).
What distinguishes the non-positroid cases is the support pattern. In TP networks, the elements appearing in non-bases always form a contiguous block — a run of consecutive indices like \(\{6, 7, 8, 9\}\). In the two non-positroid cases from negated bidiagonal training, the support has gaps: \(\{1,3,4,5\}\) (skipping 2) and \(\{3,5,6,7,8,9\}\) (skipping 4). These gapped supports are exactly the “spread” patterns from Figure 4 that break the positroid property — but now they’re arising from training, not deliberate construction.
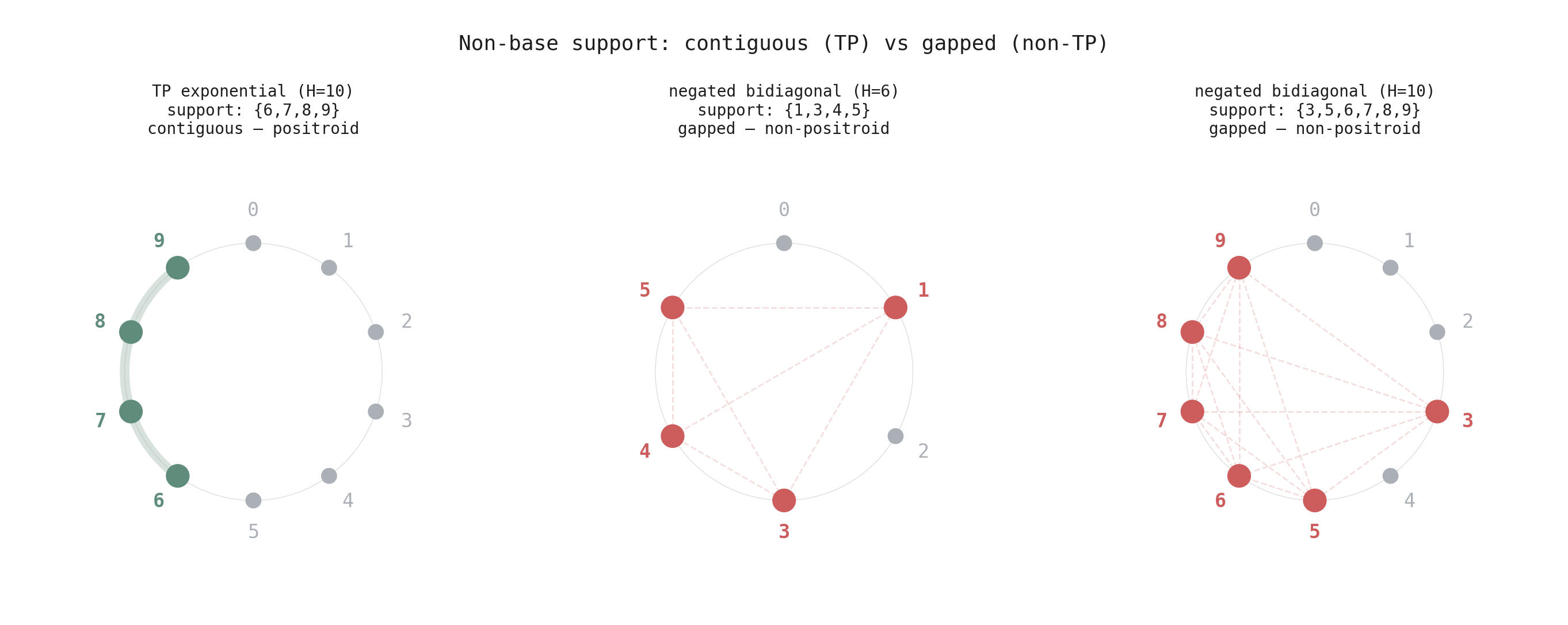
Figure 8. Non-base support on the circle. Left: TP training produces a contiguous tail — always a positroid. Center and right: non-TP training produces gapped supports — both non-positroids. The gaps are the structural signature that breaks positroid structure.
The explanation: total positivity forces the normals to converge in index order. When normals become near-collinear, they’re always neighbors — consecutive indices — so the non-base support is contiguous, and the theorem guarantees a positroid. The bidiagonal perturbation breaks this ordering, allowing non-consecutive normals to converge, creating the gaps that lead to non-positroids.
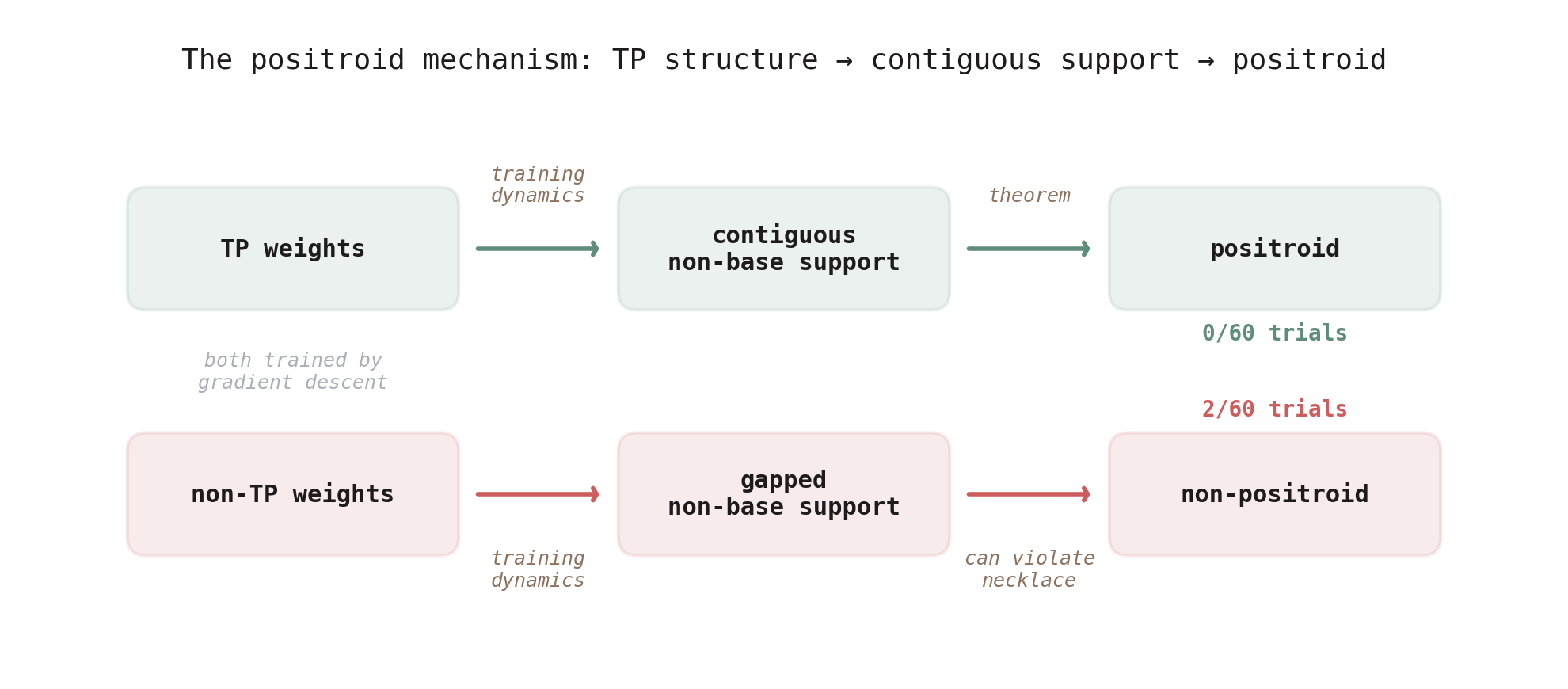
Figure 9. The full picture. TP weights produce contiguous non-base support during training, which guarantees positroid structure by theorem. Non-TP weights can produce gapped support, which breaks the positroid property. Both paths use gradient descent — the difference is the weight constraint.
The revised conjecture is now explicitly TP-specific:
For networks with TP weight matrices trained by gradient descent, the affine matroid is always a positroid.
This is a statement about the joint interaction of TP structure and gradient descent. Neither alone is sufficient: TP matrices with adversarial biases produce non-positroids (the 12,642 counterexamples), and non-TP trained networks sometimes produce non-positroids (the 2 cases above). It’s the combination that enforces positroid geometry.
All experiment code is available at github.com/HarrisonTotty/positroid-structure-relu-networks.